-
[ NLP ] 영어 텍스트 분류 (5)2020년 12월 22일 00시 01분 08초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
랜덤 포레스트 분류 모델
모델 소개
랜덤 포레스트에서는 여러 개의 의사결정 트리의 결괏값을 평균낸 것을 결과로 사용한다. 랜덤 포레스트를 통해 분류 또는 회귀를 할 수 있다. 그 전에 의사결정 트리에 대해 알아보면,
의사결정 트리란 자료구조인 트리와 같은 형태로 이루어진 알고리즘이다. 각 노드는 하나의 질문이 되고 질문에 따라 다음 노드가 달라진다.
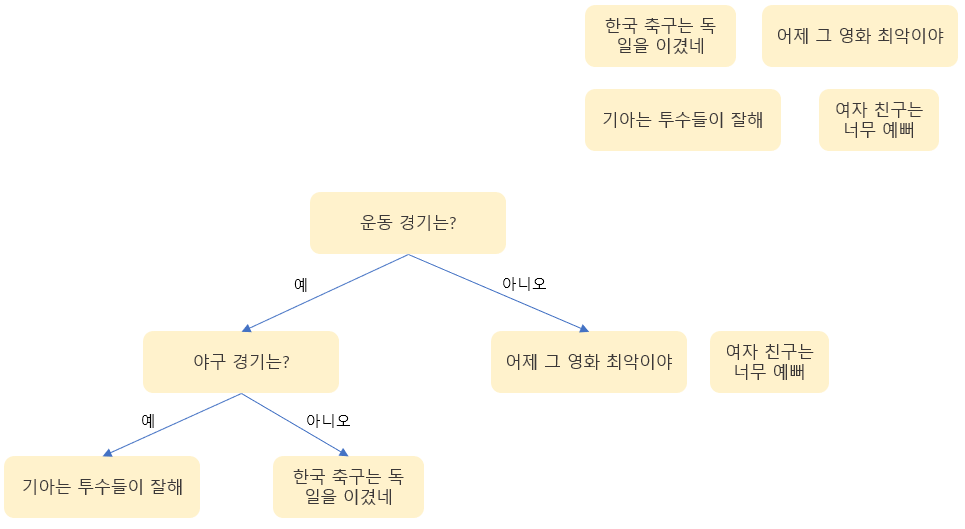
실제 의사결정 트리의 경우 훨씬 많은 가지가 있고 많은 질문으로 결과가 나온다.
이제 랜덤 포레스트란 위와 같은 트리 구조가 모여있는 형태인데, 각 트리에서 구한 결과를 종합해서 결과를 도출한다. 즉, 많은 트리를 같이 사용하면 정확도가 높아짐.
위의 4문장을 랜덤 포레스트를 통해 야구 관련 문장을 찾는다고 하자 그러면 2개의 트리를 만들 수 있을 것이다.

그렇다면 두 개의 결괏값을 합쳐 한 문장만이 야구 관련 문장이라는 것을 찾을 수 있다. 실제 랜덤 포레스트 모델에서는 2개의 의사결정 트리가 아닌 더 많은 트리들이 만들어지고 각 결과들의 평균을 내서 결과를 만든다.
CountVectorizer를 활용한 벡터화
모델 구현에 앞서 모델에 사용할 입력 값을 정해야 한다. 이전 선형 회귀 모델에서는 TF-IDF와 word2vec을 사용해 벡터화한 데이터를 입력 값으로 썼으나 랜덤 포레스트 모델에서는 CountVectorizer를 사용해 모델의 입력값을 만든다. CountVectorizer의 경우 TF-IDF와 동일하게 전처리한 텍스트 데이터를 입력값으로 사용해야 한다.
import pandas as pd import numpy as np DATA_IN_PATH='./data_in/' TRAIN_CLEAN_DATA='train_clean.csv' train_data=pd.read_csv(DATA_IN_PATH + TRAIN_CLEAN_DATA) reviews=list(train_data['review']) y=np.array(train_data['sentiment'])이제 불러온 텍스트 데이터를 특징 벡터로 만들어야 모델에 입력값으로 사용할 수 있다. CountVectorizer로 특징 추출을 한다. CountVectorizer를 불러와서 객체를 생성한 후 리뷰 텍스트 데이터를 적용한다.
from sklearn.feature_extraction.text import CountVectorizer vectorizer=CountVectorizer(analyzer="word", max_features=5000) train_data_features=vectorizer.fit_transform(reviews)그 다음 벡터화된 값을 변수에 할당한다. 객체를 생성할 때 인자 값을 설정하는데 분석 단위를 하나의 단어로 지정하기 위해 analyzer를 word로 설정하고 각 벡터의 최대 길이를 5000으로 설정했다. train_data_features의 형태를 확인해보면
train_data_features
결과를 보면 (25000,5000) 크기의 행렬로 구성된 것을 확인할 수 있는데 이는 25000개의 데이터가 각각 5000개의 특징값을 가지는 벡터로 표현돼 있다는 것을 의미한다. 이제 이 데이터를 모델에 적용하면 된다. 그 전에 학습 데이터의 일부를 검증 데이터로 만들어 모델의 성능을 측정한다.
학습과 검증 데이터 분리
이전과 동일하게 사이킷런을 활용해 검증 데이터를 만든다.
from sklearn.model_selection import train_test_split TEST_SIZE=0.2 RANDOM_SEED=42 train_input, eval_input, train_label, eval_label=train_test_split(train_data_features,y,test_size=TEST_SIZE, random_state=RANDOM_SEED)이제 학습 데이터를 사용하여 모델을 학습시킨 후 검증 데이터로 성능 측정한다.
모델 구현 및 학습
랜덤 포레스트는 사이킷런의 RandomForestClassifier 객체를 사용한다. 이 모델은 사이킷런의 ensemble 모듈 안에 있다
from sklearn.ensemble import RandomForestClassifier # 랜덤 포레스트 분류기에 100개의 의사결정 트리를 사용한다. forest=RandomForestClassifier(n_estimators=100) # 단어 묶음을 벡터화한 데이터와 정답 데이터를 가지고 학습을 시작한다. forest.fit(train_input,train_label)객체를 생성할 때 인자를 설정하는데, 이는 트리의 개수를 의미한다. 여기서는 총 100개의 트리를 만들어서 그 결과를 앙상블하고 최종 결과를 만든다. 이제 학습 데이터와 라벨을 적용해 학습시킨다.
검증 데이터셋으로 성능 평가
이제 학습시킨 모델에 따로 분리해 뒀던 검증 데이터를 사용해 성능을 평가한다.
# 검증 함수로 정확도 측정 print("Accuracy: %f" % forest.score(eval_input,eval_label))
학습시킨 모델의 score 함수로 성능을 측정했는데 대략 84%의 정확도를 가진다. 앙상블 모델이지만 앞서 사용한 모델보다 성능이 안좋다 이는 모델 문제이거나 데이터 특징 추출 방법의 문제일 수도 있다.
데이터 제출
캐글에 데이터를 제출하기 위해 전처리한 평가 데이터를 불러와 학습한 모델에 적용한 후 결과를 저장한다.
TEST_CLEAN_DATA='test_clean.csv' DATA_OUT_PATH='./data_out/' test_data=pd.read_csv(DATA_IN_PATH+TEST_CLEAN_DATA) test_reviews=list(test_data['review']) ids=list(test_data['id'])평가 데이터의 각 리뷰를 단어들의 리스트로 만들었다. 모델에 적용하기 위해 학습 데이터에 적용한 것처럼 벡터화해야 한다. 이때 학습 과정에서 정의한 vectorizer를 사용해 벡터화한다.
train_data_features=vectorizer.transform(test_reviews)이제 벡터화된 평가 데이터를 학습시킨 랜덤 포레스트 모델에 적용하고 예측값을 판다스 데이터프레임 형태로 바꿔 csv파일로 만든 후 제출한다.
import os if not os.path.exists(DATA_OUT_PATH): os.makedirs(DATA_OUT_PATH) result=forest.predict(test_data_features) output=pd.DataFrame(data={"id":ids, "sentiment":result}) output.to_csv(DATA_OUT_PATH+"Bag_of_Words_model.csv",index=False, quoting=3)
아직 90퍼센트를 못 넘는 성능을 보인다.
[ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 영어 텍스트 분류 (7) (0) 2021.01.10 [ NLP ] 영어 텍스트 분류 (6) (0) 2020.12.30 [ NLP ] 영어 텍스트 분류 (4) (0) 2020.12.14 [ NLP ] 영어 텍스트 분류 (3) (0) 2020.12.10 [ NLP ] 영어 텍스트 분류 (2) (0) 2020.12.09 댓글