-
[ NLP ] 영어 텍스트 분류 (2)2020년 12월 09일 12시 53분 55초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
데이터 전처리
이제 데이터를 모델에 적용하도록 데이터 전처리를 진행한다. 먼저 사용할 라이브러리를 보면 데이터를 다루기 위해 판다스를 사용하고, 데이터 정제를 위해 re와 Beautiful Soup을 사용한다. 그리고 불용어를 제거하기 위해 NLTK 라이브러리의 stopwords 모듈을 사용한다. 또한 텐서플로의 전처리 모듈인 pad_sequences와 Tokenizer을 사용하고, 마지막으로 전처리된 데이터를 저장하기 위해 넘파이를 사용한다.
import re import pandas as pd import numpy as np import json from bs4 import BeautifulSoup from nltk.corpus import stopwords import nltk from tensorflow.python.keras.preprocessing.sequence import pad_sequences from tensorflow.python.keras.preprocessing.text import Tokenizer nltk.download('stopwords')첫 번째 학습 데이터의 리뷰를 출력해보면
DATA_IN_PATH='./data_in/' file_list=['labeledTrainData.tsv.zip', 'unlabeledTrainData.tsv.zip', 'testData.tsv.zip'] train_data=pd.read_csv(DATA_IN_PATH+"labeledTrainData.tsv", header=0, delimiter="\t", quoting=3) # 첫 번째 리뷰 데이터 print(train_data['review'][0])
리뷰 데이터를 보면 <br>과 같은 html 태그와 '/','...' 과 같은 특수문자가 있는데 문장부호 및 특수문자는 문장의 의미에 크게 영향을 끼치지 않기에 최적화된 학습을 위해 제거한다. Beautiful Soup을 이용해 html 태그를 제거하고, re.sub을 사용해 특수문자를 제거한다.
# 리뷰 중 하나를 가져온다 review=train_data['review'][0] # HTML 태그 제거 review_text=BeautifulSoup(review,"html5lib").get_text() # 영어 문자를 제외한 나머지는 모두 공백으로 바꾼다. review_text=re.sub("[^a-zA-Z]"," ",review_text) print(review_text)
Beautiful Soup의 get_text함수를 사용하면 html태그를 제외한 텍스트만 얻을 수 있고, re의 sub함수를 사용하면 영어 알파벳을 제외한 모든 문자(숫자 및 특수기호)는 공백으로 대체한다.
다음으로는 불용어를 제거한다. 물용어는 문장에 자주 출현하나 의미에 큰 영향을 주지 않는 단어, 예를 들어 영어에서는 조사, 관사 등과 같은 어휘가 있다.
데이터에 따라 불용어를 제거하는 것은 장단점이 존재하는데, 경우에 따라 불영어가 포함된 데이터를 모델링하는 데 있어 노이즈를 줄 수 있는 요인이 될 수 있어 제거하는 것이 좋을 수 있다. 그렇지만 데이터가 많고 문장 구문에 대한 전체적 패턴을 모델링 한다면 역효과를 줄 수 있다.(지금의 경우는 감정 분석이므로 영향을 주지 않는다고 가정하고 불용어를 제거)
불용어를 제거 하려면 따로 정의한 불용어 사전을 이용해야 하는데 사용자가 직접 정의할 수 있지만 경우가 너무 많아 NLTK 라이브러리를 이용한다. 데이터에서 해당 리뷰에 포함된 단어는 모두 제거하면 된다. 그 전에 NLTK의 불용어 사전은 모두 소문자 이므로 모든 단어를 소문자로 바꾼 후 불용어를 제거한다.
# 영어 불용어 set을 만든다 stop_words=set(stopwords.words('english')) review_text=review_text.lower() # 소문자로 변환한 후 단어마다 나눠서 단어 리스트로 만든다 words=review_text.split() # 불용어를 제거한 리스트를 만든다. words=[w for w in words if not w in stop_words] print(words)
진행 과정은 lower함수로 모두 소문자로 바꾸고 이후 split 함수로 띄어쓰기를 기준으로 텍스트 리뷰를 단어 리스트로 바꾼 후 불용어에 해당하지 않는 단어만 다시 모아서 리스트로 만들었다.(중간 속도 향상을 위해 set 이용).
이를 모델에 적용하기 위해서는 다시 하나의 문자열로 합쳐야 한다. 파이썬의 join 함수를 사용해 문자열로 만든다.
# 단어 리스트를 다시 하나의 글로 합친다. clean_review=' '.join(words) print(clean_review)
결과를 보면 하나의 문자열로 바뀌었는데, 이렇게 하나하나 진행하면 25000개의 데이터에 대해 모두 적용하는 것은 불가능하다 따라서 모든 전처리 과정을 함수로 정의한다.
def preprocessing(review, remove_stopwords=False): # 불용어 제거는 옵션으로 선택 가능하다 # 1. HTML 태그 제거 review_text=BeautifulSoup(review, "html5lib").get_text() # 2. 영어가 아닌 특수문자를 공백(" ")으로 바꾸기 review_text=re.sub("[^a-zA-Z]", " ", review_text) # 3. 대문자를 소문자로 바꾸고 공백 단위로 텍스트를 나눠서 리스트로 만든다. words=review_text.lower().split() if remove_stopwords: # 4. 불용어 제거 # 영어 불용어 불러오기 stops=set(stopwords.words("english")) # 불용어가 아닌 단어로 이뤄진 새로운 리스트 생성 words=[w for w in words if not w in stops] # 5. 단어 리스트를 공백을 넣어서 하나의 글로 합친다. clean_review=' '.join(words) # 불용어를 제거하지 않을 때 else: clean_review=' '.join(words) return clean_review다음으로 함수를 사용해 전체 데이터에 대해 전처리를 진행한 후 데이터 하나를 확인해본다.
clean_train_reviews=[] for review in train_data['review']: clean_train_reviews.append(preprocessing(review,remove_stopwords=True)) # 전처리한 데이터의 첫 번째 데이터 출력 clean_train_reviews[0]
이제 두 가지 전처리 과정이 남았는데, 먼저 전처리한 데이터에서 각 단어를 인덱스로 벡터화해야하고, 모델에 따라 입력값의 길이가 동일해야 하기 때문에 일정 길이로 자르고 부족한 부분은 특정값으로 채우는 패딩 과정을 진행해야한다. 하지만 모델에 따라 각 리뷰가 단어들의 인덱스로 구성된 벡터가 아닌 텍스트로 구성돼야 하는 경우도 있다. 따라서 지금까지 전처리한 데이터를 판다스의 데이퍼프레임으로 만들어 두고 이후 전처리 과정이 모두 끝난 후 전처리한 데이터를 저장할 때 함께 저장하게 한다.
clean_train_df=pd.DataFrame({'review':clean_train_reviews, 'sentiment':train_data['sentiment']})이제 모델에 따라 입력값이 텍스트가 아닌 각 단어의 인덱스로 되어 있어야 하고, 동일한 길이여야 하는 경우가 있기 때문에 이 과정을 진행한다. 여기서는 텐서플로우의 전처리 모듈을 사용하는데 우선 Tokenizer 모듈을 생성 후 정제된 데이터에 적용하고 인덱스로 구성된 벡터로 변환한다. 그리고 첫 번쨰 값을 출력해본다.
tokenizer=Tokenizer() tokenizer.fit_on_texts(clean_train_reviews) text_sequences=tokenizer.texts_to_sequences(clean_train_reviews) print(text_sequences[0])
결과를 보면 첫 번째 리뷰가 각 단어의 인덱스로 바뀌었다. 이제는 데이터가 인덱스로 구성돼 있는데, 각 인덱스가 어떤 단어를 의미하는지 확인할 수 있어야 한다. 따라서 단어 사전을 확인해보면,
word_vocab=tokenizer.word_index print(word_vocab)
다음으로 전체 데이터의 단어 개수를 보면
print("전체 단어 개수: ", len(word_vocab))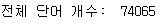
단어 사전뿐 아니라 전체 단어 개수도 이후 모델에서 사용되기에 저장해 둔다. 데이터에 대한 정보인 단어 사전과 전체 단어 개수는 새롭게 딕셔너리 값으로 지정해 저장한다.
data_configs={} data_configs['vocab']=word_vocab data_configs['vocab_size']=len(word_vocab)+1이제 마지막 전처리로, 현재 각 데이터는 서로 길이가 다른데 이 길이를 하나로 통일해야 이후 모델에 바로 적용할 수 있기에 특정 길이를 최대 길이로 정하고 더 긴 데이터는 뒷 부분을 자르고, 짧은 데이터는 0값으로 패딩하는 작업을 진행한다.
# 문장 최대 길이 MAX_SEQUENCE_LENGTH=174 train_inputs=pad_sequences(text_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post') print('Shape of train data: ',train_inputs.shape)
패딩 처리에는 pad_sequences 함수를 썼는데 인자로 패딩을 적용할 데이터, 최대 길이 값, 0 값을 데이터 앞에 넣을지 뒤에 넣을지 설정한다.
최대 길이를 174로 정한 이유는 단어 개수 통계의 중간값인데, 보통 평균이 아닌 중간값을 사용하는 경우가 많다. 그 이유는 일부 이상치 데이터가 길이가 너무 길면 평균이 급격히 올라갈 수 있기 때문이다. 패딩 처리로 데이터의 형태가 25,000개 모두 174라는 길이를 가지게 되었다.
마지막으로 학습 시 라벨, 즉 정답을 나타내는 값을 넘파이 배열로 저장한다. 넘파이 배열로 변환하는 이뉴는 이후 전처리한 데이터를 저장할 때 넘파이 형태로 저장하기 때문.
train_labels=np.array(train_data['sentiment']) print("Shape of label tensor:",train_labels.shape)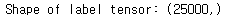
넘파이 배열로 만든 후 라벨 형태를 보면 길이가 25,000인 벡터임을 확인할 수 있다. 데이터 하나당 하나의 값을 가지는 형태이다.
단어를 벡터화 하고 패팅하는 과정을 직관적으로 보면
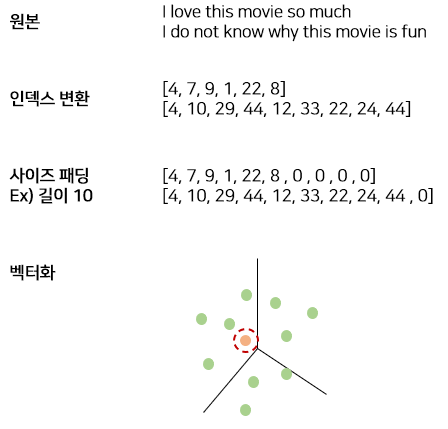
이제 전처리한 데이터를 이후 모델링 과정에서 사용하기 위해 저장한다. 총 4개의 데이터를 저장할 것이다.
- 정제된 텍스트 데이터
- 백터화한 데이터
- 정답 라벨
- 데이터 정보(단어 사전, 전체 단어 개수)
텍스트의 경우 csv파일로, 벡터화한 데이터와 정답 라벨은 넘파이 파일로 저장한다. 데이터 정보의 경우 딕셔너리 형태이기에 JSON 파일로 저장한다.
DATA_IN_PATH='./data_in/' TRAIN_INPUT_DATA='train_input.npy' TRAIN_LABEL_DATA='train_label.npy' TRAIN_CLEAN_DATA='train_clean.csv' DATA_CONFIGS='data_configs.json' import os # 저장하는 디렉터리가 존재하지 않으면 생성 if not os.path.exists(DATA_IN_PATH): os.makedirs(DATA_IN_PATH) # 전처리된 데이터를 넘파이 형태로 저장 np.save(open(DATA_IN_PATH + TRAIN_INPUT_DATA, 'wb'), train_inputs) np.save(open(DATA_IN_PATH + TRAIN_LABEL_DATA, 'wb'), train_labels) # 정제된 텍스트를 CSV로 저장 clean_train_df.to_csv(DATA_IN_PATH + TRAIN_CLEAN_DATA, index=False) # 데이터 사전을 JSON 형태로 저장 json.dump(data_configs, open(DATA_IN_PATH + DATA_CONFIGS, 'w'), ensure_ascii=False)
지금까지는 학습데이터의 전처리를 했으므로 평가 데이터에 대해서도 동일 과정을 진행한다. 다른 점은 평가 데이터의 경우 라벨 값이 없기에 라벨은 따로 저장하지 않아도 되고 데이터 정보인 단어 사전과 단어 개수도 학습 데이터의 것을 사용하기에 저장하지 않아도 된다. 추가로 평가 데이터에 대해서는 각 리부에 대한 id값을 저장해야한다.
test_data=pd.read_csv(DATA_IN_PATH + "testData.tsv", header=0, delimiter="\t") clean_test_reviews=[] for review in test_data['review']: clean_test_reviews.append(preprocessing(review, remove_stopwords=True)) clean_test_df=pd.DataFrame({'review':clean_test_reviews, 'id':test_data['id']}) test_id=np.array(test_data['id']) tokenizer.fit_on_texts(clean_test_reviews) text_sequences=tokenizer.texts_to_sequences(clean_test_reviews) test_inputs=pad_sequences(text_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post')평가 데이터를 전처리할 때 중요한 것은 토크나이저를 통해 인덱스 벡터로 만들 때 토크나이징 객체로 새롭게 만드는게 아닌 기존에 학습 데이터에 적용한 토크나이저 객체를 사용해야 한다는 것이다. 만약 새롭게 만들 경우 학습 데이터와 평가 데이터에 대한 각 단어들의 인덱스가 달라져서 모델에 적용할 수 없기 때문이다.
평가데이터도 저장한다.
TEST_INPUT_DATA='test_input.npy' TEST_CLEAN_DATA='test_clean.csv' TEST_ID_DATA='test_id.npy' np.save(open(DATA_IN_PATH + TEST_INPUT_DATA, 'wb'), test_inputs) np.save(open(DATA_IN_PATH + TEST_ID_DATA, 'wb'), test_id) clean_test_df.to_csv(DATA_IN_PATH + TEST_CLEAN_DATA, index=False)
[ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 영어 텍스트 분류 (4) (0) 2020.12.14 [ NLP ] 영어 텍스트 분류 (3) (0) 2020.12.10 [ NLP ] 영어 텍스트 분류 (1) (0) 2020.12.08 [ kaggle ] kaggle api 사용하기 (0) 2020.12.08 [ NLP ] 탐색적 데이터 분석 (0) 2020.12.05 댓글