-
[ NLP ] 영어 텍스트 분류 (6)2020년 12월 30일 14시 35분 06초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
순환 신경망 분류 모델
앞서 진행한 모델들은 머신러닝 활용이고, 이번부터는 딥러닝을 활용해 분류하는 모델을 진행한다. 순환 신경망은 언어 모델에서 많이 쓰이는 딥러닝 모델이다. 주로 순서가 있는 데이터, 즉 문장 데이터를 입력해서 문장 흐름에서 패턴을 찾아 분류하게 한다. 앞선 모델들과 달리 이미 주어진 단어 특징 벡터를 활용해 모델을 학습하지 않고 텍스트 정보를 입력해서 문장에 대한 특징 정보를 추출한다.
모델 소개
순환 신경망(RNN)은 "현재 정보는 이전 정보가 점층적으로 쌓이면서 정보를 표현할 수 있는 모델"
따라서 시간에 의존적인 또는 순차적인 데이터에 대한 문제에 활용된다.

위 그림은 한 언어 모델을 순환 신경망의 구조로 나타낸 것으로 이 모델은 한 단어에 대한 정보를 입력하면 다음 단어를 맞추는 모델이다. 우선 '나는'이라는 단어 정보를 모델에 입력하서 다음 나올 단어를 예측하고, 그 다음 "가방을"이라는 정보를 입력한다고 하자. 이 상황에서 현재 입력한느 단어인 "가방을" 다음에 나올 단어를 단순히 "가방을"만 가치고 예측하지 않고 앞서 입력된 "나는"과 함께 활용하여 단어를 예측한다. 여기서 현재 정보 "가방을"을 입력상태(input state), 이전 정보를 은닉상태(hidden state)라고 부른다. 순환 신경망은 이 두 정보를 통해 순서가 있는 데이터에 대한 예측 모델링을 가능하게 함.
여기서는 이런 방식으로 동작하는 순환 신경망을 가지고 영화 평점 예측 모델을 만든다.
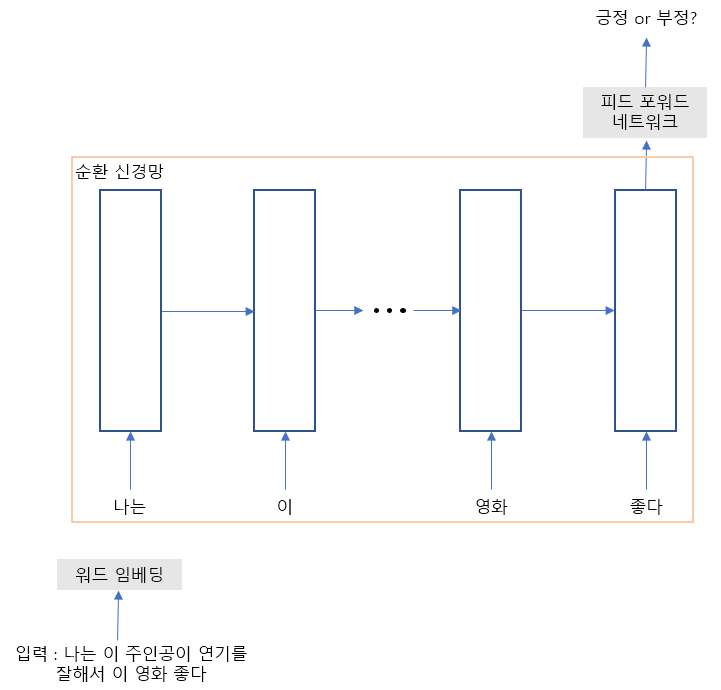
영화 평점 예측을 위한 순환 신경망 모델 앞서 설명 예시와는 다르게 입력 문장을 순차적으로 입력만 하고 마지막 입력한 시점에 출력 정보를 뽑아 영화 평점을 예측한다. 매 시간 스텝에 따라 입력되는 입력 정보는 은닉상태를 통해 정보를 다음 시간 스템으로 전달하도록 함. 마지막 시간 스텝에 나온 은식 상태는 문장 전체 정보가 담긴 정보로 이 정보를 활용하여 영화 평점을 예측할 수 있도록 로지스틱 회귀 또는 이진 분류를 하면 된다.
학습 데이터 불러오기
tf.estimator을 활용해 모델 학습을 할거다.
import pandas as pd import numpy as np import json DATA_IN_PATH='./data_in/' DATA_OUT_PATH='./data_out' INPUT_TRAIN_DATA_FILE_NAME='train_input.npy' LABEL_TRAIN_DATA_FILE_NAME='train_label.npy' DATA_CONFIGS_FILE_NAME='data_configs.json' input_data=np.load(open(DATA_IN_PATH+INPUT_TRAIN_DATA_FILE_NAME,'rb')) label_data=np.load(open(DATA_IN_PATH+LABEL_TRAIN_DATA_FILE_NAME,'rb')) prepro_config=None with open(DATA_IN_PATH+DATA_CONFIGS_FILE_NAME,'r') as f: prepro_congih=json.load(f)앞 절에서 전처리를 했으므로 파일을 불러오는 작업을 했다.
학습과 검증 데이터셋 분리
학습 데이터의 일부는 모델 하이퍼파라미터에 튜닝을 위해 검증 데이터셋이 필요하다. 여기서는 사이킷런을 사용해 학습, 검증 데이터셋을 구분
from sklearn.model_selection import train_test_split TEST_SPLIT=0.1 RANDOM_SEED=13371447 train_input, test_input, train_label, test_label=train_test_split(input_data,label_data,test_size=TEST_SPLIT,random_state=RANDOM_SEED)
데이터 입력 함수
학습, 평가 데이터셋이 준비되면 데이터 입력 함수를 구현한다.
import tensorflow as tf BATCH_SIZE=16 NUM_EPOCHS=3 def mapping_fn(X, Y): inputs, labels={'x':X},Y return inputs, labels def train_input_fn(): dataset=tf.data.Dataset.from_tensor_slices((train_input, train_label)) dataset=dataset.shuffle(buffer_size=1000) dataset=dataset.batch(BATCH_SIZE) dataset=dataset.map(mapping_fn) dataset=dataset.repeat(count=NUM_EPOCHS) iterator=dataset.make_one_shot_iterator() return iterator.get_next() def eval_input_fn(): dataset=tf.data.Dataset.from_tensor_slices((test_input,test_label)) dataset=dataset.map(mapping_fn) dataset=dataset.batch(BATCH_SIZE) iterator=dataset.make_one_shot_iterator() return iterator.get_next()데이터 입력 함수는 모델에 학습 데이터를 주입하는 방법인데, 함수에서는 tf.data를 활용해 입력 데이터를 하나의 파이프라인을 거쳐 모델에 입력한다. 다음 모델 함수 구현.
모델 함수
tf.estimator를 활용하기 위해서는 모델 그래프에 대한 정의를 함수에 구현해야 한다.
모델 하이퍼파라미터 정의
단어 사전에 대한 크기를 정해야 함.
VOCAB_SIZE=prepro_configs['vocab_size']앞서 학습 데이터에 대한 단어 사전을 저장했으므로 이제 모델에 대한 하이퍼 파라미터 변수의 차원과 학습률을 정한다.
WORD_EMBEDDING_DIM=100 HIDDEN_STATE_DIM=150 DENSE_FEATURE_DIM=150 learning_rate=0.001하이퍼 파라미터는 모델에 고정되는 값이고 학습 후에는 변경 불가능.
모델 구현
먼저 모델 함수에 들어갈 내용을 구현한다.
def model_fn(features, labels, mode): TRAIN=mode==tf.estimator.ModeKeys.TRAIN EVAL=mode==tf.estimator.ModeKeys.EVAL PREDICT=mode==tf.estimator.ModeKeys.PREDICT embedding_layer=tf.keras.layers.Embedding(VOCAB_SIZE,WORD_EMBEDDING_DIM)(features['x']) embedding_layer=tf.keras.layers.Dropout(0.2)(embedding_layer) rnn_layers=[tf.nn.rnn_cell.LSTMCell(size) for size in [HIDDEN_STATE_DIM, HIDDEN_STATE_DIM]] multi_rnn_cell=tf.nn.rnn_cell.MultiRNNCell(rnn_layers) outputs,state=tf.nn.dynamic_rnn(cell=multi_rnn_cell,inputs=embedding_layer,dtype=tf.float32) outputs=tf.keras.layers.Dropout(0.2)(outputs) hidden_layer=tf.keras.layers.Dense(DENSE_FEATURE_DIM,activation=tf.nn.tanh)(outputs[:,-1,:]) hidden_layer=tf.keras.layers.Dropout(0.2)(hidden_layer) logits=tf.keras.layers.Dense(1)(hidden_layer) logits=tf.squeeze(logits, axis=-1) sigmoid_logits=tf.nn.sigmoid(logits) if PREDICT: predictions={'sentiment':sigmoid_logits} return tf.estimator.EstimatorSpec(mode=mode,predictions=predictions) loss=tf.losses.sigmoid_cross_entropy(labels, logits) if EVAL: accuracy=tf.metrics.accuracy(labels, tf.round(sigmoid_logits)) eval_metric_ops={'acc':accuracy} return tf.estimator.EstimatorSpec(mode, loss=loss,eval_metric_ops=eval_metric_ops) if TRAIN: global_step=tf.train.get_global_step() train_op=tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step) return tf.estimator.EstimatorSpec(mode=mode,train_op=train_op,loss=loss)위 코드는 함수 천체이고 임베딩 층부터 차근차근 보면
embedding_layer=tf.keras.layers.Embedding(VOCAB_SIZE,WORD_EMBEDDING_DIM)(features['x'])먼저 모델에서 배치 데이터를 받게되면 단어 인덱스로 구성된 시퀀스 형태로 입력이 들어온다. 데이터 입력 함수에서 정의했듯 모델 함수의 입력 인자인 features는 파이썬 딕셔너리 형태로 구성되어 있다.
모델에 들어온 입력 데이터는 보통 임베딩 층을 거친다. 여기서는 tf.keras.Embedding이 이 역할을 수행.
이제 순환 신경망을 구현한다.
embedding_layer=tf.keras.layers.Embedding(VOCAB_SIZE,WORD_EMBEDDING_DIM)(features['x']) embedding_layer=tf.keras.layers.Dropout(0.2)(embedding_layer)임베딩 층을 거친 데이터는 순환 신경망 층을 거쳐 문장의 의미 벡터를 출력한다. 여기서는 간단한 심층 순환 신경망(Deep RNN) 모델은 LSTM 모델을 통해 구현한다.
순환 신경망을 구현하기 위해 텐서플로의 RNNCell 객체를 활용함.(RNNCell은 순환 신경망 객체라 보면 됨.)
LSTM으로 순환 신경망을 구현하기 위해 tf.nn.rnn_cell.LSTMCell객체를 생성한다. 이 객체는 하나의 LSTM Cell을 의미 함.
따라서 해당 Cell객체를 여러개 생성해서 하나의 리스트로 만든다. LSTMCell을 생성할 떄는 은닉 상태 벡터에 대한 차원만 정의하면 된다.
여러 LSTMCell을 쌓게 되면 이를 하나의 MultiRNN으로 묶어야 한다. 즉, 이게 래핑(wrapping).
tf.nn.rnn_cell.MultiRNNCell을 생성함으로써 스택 구조의 LSTM 신경망을 구현할 수 있음.
# 네트워크와 임베딩 벡터와 연산하기 위해 dynamic_rnn 함수를 선언한다. outputs,state=tf.nn.dynamic_rnn(cell=multi_tnn_cell,inputs=embedding_layer,dtype=tf.float32)단순히 RNNCell만으로 구성해 모델 연산 그래프를 만들 수 있다. RNNCell객체는 시퀀스 한 스텝에 대한 연산만 가능함. 따라서 여러 스텝에 대한 연산을 위해 for문으로 구현.
그러나 더 간단하게 구현하도록 텐서플로에서 제공한다. tf.nn.dynamic_rnn 함수는 for문 없이 자동으로 순환 신경망을 만들어 줌.
dynamic_rnn 함수에 필요한 인자는 2개다. 첫 번째는 순환 신경망 객체인 MultiRNNCell객체로 앞에서 이미 multi_rnn_cell 변수로 객체를 저장했다. 두 번째 인자는 입력값이다. 그리고 dtype 인자로 출력값의 데이터 타입을 설정할 수 있다. 그리고 이 함수를 통해 나온 출력값에 tf.keras.layers.Dense를 적용시킨다.
hidden_layer=tf.keras.layers.Dense(DENSE_FEATURE_DIM,activation=tf.nn.tanh)(outputs[:,-1,:])Dense에 적용시키는 입력값은 LSTM 신경망의 마지막 출력값을 넣어준다. 출력값에 [:,-1,:로 마지막 값만 뽑아낸 후 Dense에 적용시킨다. 그리고 활성화 함수는 하이퍼블릭 탄젠트 함수를 사용함.
# 최종적으로 1 dim의 output만 할 수 있도록 dense layer를 활용해 차원을 변환한다. logits=tf.keras.layers.Dense(1)(hidden_layer)마지막으로 감정이 긍정인지 부정인지 판단하도록 출력값을 하나로 만들어야 한다. 보통 선형 변환을 통해 입력 벡터에 대한 차원 수를 바꾼다. 여기서는 tf.keras.layers.Dense함수가 이 역할을 함.
은닉층 구현과 동일하게 Dense 객체를 생성하고 호출 시 units 인자에 1을 입력한다.
이렇게 구현하면 감정 분류 모델을 만들게 된다. 다음으로 모델 학습을 위해 어떻게 구현하는지 보면,
모델 학습을 위한 구현
모델에서 구현한 값과 정답 라벨을 가지고 손실값을 구해 아담 옵티마이저를 사용해 모델 파라미터를 최적화한다.
loss=tf.losses.sigmoid_cross_entropy(labels, logits) global_step=tf.train.get_global_step() train_op=tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step)모델 예측 로스값은 모델에서 구한 logits 변수와 정답인 labels 변수를 가지고 구한다. logits 변수는 아직 로지스틱 함수로 0~1사이 값으로 스케일 조정을 안했다. 물론 dense 층에서 activation 인자를 tf.nn.sigmoid로 설정할 수 있다. 하지만 여기서는 tf.losses.sigmoid_cross_entropy 함수로 손실값을 구할 수 있기에 dense층에서 설정 안했다.
예측 손실값을 구하면 파라미터 최적화 하고자 경사도 하강법을 아담 옵티마이저로 진행한다. AdamOptimizer 객체 생성할 때 생성자 입력 인자로 학습률 값을 입력한다.
tf.train.AdamOptimizer.minimize 함수를 선언할 때 전체 학습에 대한 글로벌 스텝 값을 넣어야한다. tf.train.get_global_step을 선언하면 현재 학습 글로벌 스텝을 얻을 수 있다.
return tf.estimator.EstimatorSpec(mode=mode,train_op=train_op,loss=loss)보통 직접 모델 함수를 구현하게 되면 tf.estimator.EstimatorSpec 객체를 생성하여 반환하게 한다. 이 객체는 현재 함수가 어느 모드에서 실행되고 있는지 확인하고 각 모드에 따라 필요한 입력 인자가 다르다.
학습을 하는 경우는 EstimatorSpec에서 학습 연산과 손실값이 필요하다. 앞서 구현한 내용에서 train_op와 loss변수를 입력한다. mode 변수는 앞서 모델 함수의 입력 인자값을 그대로 받으면 된다.
모델 평가를 위한 구현
모델 학습을 마치면 모델 성능이 어떤지 확인할 필요가 있다. 모델 평가 코드를 구현하면
accuracy=tf.metrics.accuracy(labels, tf.round(sigmoid_logits)) eval_metric_ops={'acc':accuracy} return tf.estimator.EstimatorSpec(mode, loss=loss,eval_metric_ops=eval_metric_ops)여기서는 감정 예측값이 정답 라벨과 얼마나 일치하는지 정확도를 본다. 정확도는 tf.metrics.accuracy를 통해 나타낼 수 있다. 이 결과를 tf.estimator.EstimatorSpec의 eval_metric_ops인자로 입력하면 평가 결과를 확인할 수 있다.
모델 예측을 위한 구현
모델 성능을 평가하고 나면 캐글에 평가할 데이터를 가지고 예측해야 한다. 예측하는 방법은
sigmoid_logits=tf.nn.sigmoid(logits) predictions={'sentiment':sigmoid_logits} return tf.estimator.EstimatorSpec(mode=mode,predictions=predictions)우선 모델 출력값에 대해 0~1사이 값으로 만들기 위해 tf.nn.sigmoid 함수를 활용한다. 이렇게 나온 결과는 dict객체로 표현하여 에스티메이터에서 반환할 예측값을 만든다. 여기서는 출력할 예측 값에 대한 key를 'sentiment'로 정의했고 이를 tf.estimator.EstimatorSpec의 인자인 prediction에 입력하면 예측값을 반환할 수 있다.
이제 구현한 모델 함수로 tf.을 활용한다.
TF Estimator 활용
이제 모델을 작성한 함수로 에스티메이터 객체를 생성한다.
import os if not os.path.exists(DATA_OUT_PATH): os.makedirs(DATA_OUT_PATH) est=tf.estimator.Estimator(model_fn,model_dir=DATA_OUT_PATH+'checkpoint/rnn')tf.estimator.Estimator객체를 생성한다. 생성시 인자로는 작성한 모델 함수 이름을 입력한다. 생성한 객체를 통해 학습과 평가, 예측 등의 실행이 가능하다.
TF Estimator를 활용한 학습 및 성능 검증
구현했던 데이터 입력 함수와 TF Estimator로 모델 학습한다.
est.train(train_input_fn)책을 보면서 여기까지 진행했지만 tensorflow 버전으로 인한 문제가 생겼다.
텐서플로 v1에서 v2로 가면서 변한게 많은 것 같다. 이를 v1 코드로 바꿔줘야한다.
구글링 해서 어떻게 수정을 완료했다. 다시 함수를 확인하여 코드를 바꿔준다.
def train_input_fn(): dataset=tf.data.Dataset.from_tensor_slices((train_input, train_label)) dataset=dataset.shuffle(buffer_size=1000) dataset=dataset.batch(BATCH_SIZE) dataset=dataset.map(mapping_fn) dataset=dataset.repeat(count=NUM_EPOCHS) iterator=tf.compat.v1.data.make_one_shot_iterator(dataset) #dataset.make_one_shot_iterator() return iterator.get_next()def model_fn(features, labels, mode): TRAIN=mode==tf.estimator.ModeKeys.TRAIN EVAL=mode==tf.estimator.ModeKeys.EVAL PREDICT=mode==tf.estimator.ModeKeys.PREDICT embedding_layer=tf.keras.layers.Embedding(VOCAB_SIZE,WORD_EMBEDDING_DIM)(features['x']) embedding_layer=tf.keras.layers.Dropout(0.2)(embedding_layer) #rnn_layers=[tf.nn.rnn_cell.LSTMCell(size) for size in [HIDDEN_STATE_DIM, HIDDEN_STATE_DIM]] 밑부분 계속 읽으면서 수정 rnn_layers=[tf.compat.v1.nn.rnn_cell.LSTMCell(size) for size in [HIDDEN_STATE_DIM, HIDDEN_STATE_DIM]] #multi_rnn_cell=tf.nn.rnn_cell.MultiRNNCell(rnn_layers) multi_rnn_cell=tf.compat.v1.nn.rnn_cell.MultiRNNCell(rnn_layers) outputs,state=tf.compat.v1.nn.dynamic_rnn(cell=multi_rnn_cell,inputs=embedding_layer,dtype=tf.float32) outputs=tf.keras.layers.Dropout(0.2)(outputs) hidden_layer=tf.keras.layers.Dense(DENSE_FEATURE_DIM,activation=tf.nn.tanh)(outputs[:,-1,:]) hidden_layer=tf.keras.layers.Dropout(0.2)(hidden_layer) logits=tf.keras.layers.Dense(1)(hidden_layer) logits=tf.squeeze(logits, axis=-1) sigmoid_logits=tf.nn.sigmoid(logits) if PREDICT: predictions={'sentiment':sigmoid_logits} return tf.estimator.EstimatorSpec(mode=mode,predictions=predictions) loss=tf.compat.v1.losses.sigmoid_cross_entropy(labels, logits) if EVAL: accuracy=tf.metrics.accuracy(labels, tf.round(sigmoid_logits)) eval_metric_ops={'acc':accuracy} return tf.estimator.EstimatorSpec(mode, loss=loss,eval_metric_ops=eval_metric_ops) if TRAIN: global_step=tf.compat.v1.train.get_global_step() train_op=tf.compat.v1.train.AdamOptimizer(learning_rate).minimize(loss, global_step) return tf.estimator.EstimatorSpec(mode=mode,train_op=train_op,loss=loss)import os if not os.path.exists(DATA_OUT_PATH): os.makedirs(DATA_OUT_PATH) est=tf.estimator.Estimator(model_fn,model_dir=DATA_OUT_PATH+'checkpoint/rnn')est.train(train_input_fn)진행하면서 노트북이 불나는 줄 알았다.
앞서 생성한 에스티메이터 객체인 est에 대해 train 함수를 호출하면 간단히 모델 학습이 진행되는데, 주어진 입력 데이터 함수에서 정의한 데이터에 대해 한습을 진행하고 여기서 정의한 입력 데이터 함수는 전체 데이터를 한 번씩 학습하는 것으로 정의해 뒀다. 이를 보통 1 에폭이라고 함.
매번 함수를 호출할 때마다 모델은 한 에폭에 대한 학습을 진행한다.
학습을 했다면 모델을 평가한다.
est.evaluate(eval_input_fn)역시 텐서플로 버전 문제가 발생했는데
def eval_input_fn(): dataset=tf.compat.v1.data.Dataset.from_tensor_slices((test_input,test_label)) dataset=dataset.map(mapping_fn) dataset=dataset.batch(BATCH_SIZE) iterator=dataset.make_one_shot_iterator() return iterator.get_next()if EVAL: accuracy=tf.compat.v1.metrics.accuracy(labels, tf.round(sigmoid_logits)) eval_metric_ops={'acc':accuracy} return tf.estimator.EstimatorSpec(mode, loss=loss,eval_metric_ops=eval_metric_ops)이렇게 수정해 줘야한다.
그리고 수정했으므로
est.train(train_input_fn)으로 다시 학습해줘야한다....
학습 후 다시 평가하면
est.evaluate(eval_input_fn)아래와 같은 결과를 가질 수 있다.
{'acc': 0.8056, 'loss': 0.4432413, 'global_step': 8442}
evaluation 함수는 현재 학습한 모델에 대해 평가 데이터셋을 활용해 모델 성능이 어느정도인지 확인하게 한다. Estimator.train 함수와 마찬가지로 데이터 입력 함수를 인자로 입력한다. 여기서는 eval_input_fn을 입력했다. 이렇게 evaluate 함수를 호출하면 해당 입력 데이터셋에 대해 정의한 성능 기준 점수 형식에 맞게 출력한다. 이 경우는 정확도를 성능 기준으로 봤기에 위 결과로 나왔다.
그리고 자꾸 버전 문제가 발생했는데 한번에 이를 해결하려면 애초에 import 할때 v1으로 하면 되는 것 같다....
import tensorflow.compat.v1 as tf
데이터 제출
캐글 제출 데이터를 만든다.
TEST_INPUT_DATA='test_input.npy' test_input_data=np.load(open(DATA_IN_PATH+TEST_INPUT_DATA,'rb'))앞서 전처리한 평가 데이터셋을 numpy.load로 받는다.
predict_input_fn=tf.compat.v1.estimator.inputs.numpy_input_fn(x={"x":test_input_data},shuffle=False)에스티메이터로 예측하라면 데이터 입력 함수를 정의해야 했다. 그 경우는 estimator.estimator.inputs.numpy_input_fn로 데이터 입력 함수를 생성함
predictions=np.array([p['sentiment'] for p in est.predict(input_fn=predict_input_fn)])모델을 통해 예측하는 데이터를 estimator.predict 함수를 통해 보자. 앞서 모델 함수에서 구현했듯 'sentiment'라는 키로 결과를 받는다.
이제 데이터를 제출하기 위해 평가 데이터의 id값을 불러오고 제출한다.
TEST_ID_DATA='test_id.npy' test_id=np.load(open(DATA_IN_PATH+TEST_ID_DATA,'rb'),allow_pickle=True) output=pd.DataFrame(data={"id":test_id,"sentiment":list(predictions)}) output.to_csv(DATA_OUT_PATH+"rnn_predict.csv",index=False,quoting=3)결과를 보면

기존보다 높게 나오긴 했는데 책보다는 낮게 나왔다. 왜그러지...?
[ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 한글 텍스트 분류 (1) (0) 2021.01.12 [ NLP ] 영어 텍스트 분류 (7) (0) 2021.01.10 [ NLP ] 영어 텍스트 분류 (5) (0) 2020.12.22 [ NLP ] 영어 텍스트 분류 (4) (0) 2020.12.14 [ NLP ] 영어 텍스트 분류 (3) (0) 2020.12.10 댓글