-
[ NLP ] 영어 텍스트 분류 (3)2020년 12월 10일 21시 13분 57초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
모델링 소개
전까지는 전처리를 진행했고, 이제 앞의 결과로 나온 전처리 데이터를 집적 모델에 적용하고 주어진 텍스트에 대해 감정이 긍정인지 부정인지 예측하는 모델을 만든다. 여러 모델 사용 예정
실습할 모델
머신러닝 모델 중 선형 회귀 모델, 랜덤 포레스트 모델로 감정 분석 (사이킷런 사용)
딥러닝 모델 중 합성곱 신경망(CNN) 모델, 순환 신경망(RNN) 모델 (텐서플로우 사용)
회귀 모델
딥러닝 모델을 시작하기 앞서 간단한 모델을 만든다. 만들 모델은 로지스틱 회귀 모델이다. 로지스틱 회귀 모델은 주로 이항 분류를 하기 위해 사용되는 분류 문제에서 사용할 수 있는 가장 간단한 모델이다. 로지스틱 회귀는 선형결합을 통해 나온 결과를 토대로 예측하게 된다. 모델 소개에 앞서 선형 회귀 모델을 알아본다.
선형 회귀 모델
선형 모델은 종속변수와 독립변수 간의 상관관계를 모델링하는 기법이다. 간단히 하나의 선형 방정식으로 표현해 예측할 데이터를 분류하는 모델이라고 생각하면됨 예를 들어
이 데이터를 2개의 범주로 분류해야 한다. 이때 하나의 직선으로 데이터를 구분하면

위의 직선으로 표현할 수 있다.
선형 회귀 모델을 수식으로 표현하면,
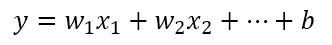
선형 회귀 모델 위 식의 w값들과 b는 학습하고자 하는 파라미터이고 x값들은 입력값이다. 여기서 모델에 입력하는 값은 바로 x 변수들에 넣게 된다. 변수 x들에는 주로 단어 또는 문장 표현 벡터를 입력하게 된다. 더불어 x1, x2로 다루지 않고 벡터 x로 다루게 된다.
로지스틱 회귀 모델
선형 모델의 결괏값에 로지스틱 함수를 적용해 0~1사이의 값으로 확률을 표현. 결과를 통해 1에 가까우면 정답이 1이라 예측하고 0에 가까우면 0으로 예측함.
이제 로지스틱 모델로 텍스트를 분류하면, 여기서는 입력값은 단어를 word2vec으로 단어 임베딩 벡터로 만드는 법과 tf-idf로 임베딩 벡터로 만드는 법 모두 사용한다.
TF-IDF를 활용한 모델 구현
TF-IDF를 활용해 문장 벡터를 만든다. 입력 값에 TF-IDF 값으로 벡터화를 진행하기에 사이킷런의 TfidfVectorizer를 사용한다. 이를 사용하기 위해서는 입력값이 텍스트로 이루어진 데이터 형태여야 한다. 따라서 전처리 한 것 중 넘파이 배열이 아닌 정제된 텍스트 제이터를 사용한다. 데이터를 불러오면
import re import pandas as pd import numpy as np import json import os DATA_IN_PATH='./data_in/' TRAIN_CLEAN_DATA='train_clean.csv' train_data=pd.read_csv(DATA_IN_PATH+TRAIN_CLEAN_DATA, header=0,quoting=3) reviews=list(train_data['review']) sentiments=list(train_data['sentiment'])TF-IDF 벡터화
이제 데이터에 대해 TF-IDF 값으로 벡터화를 한다.
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer=TfidfVectorizer(min_df=0.0, analyzer="char", sublinear_tf=True, ngram_range=(1,3), max_features=5000) X=vectorizer.fit_transform(reviews)객체를 생성할 때 몇가지 인자값을 설정하는데, min_df는 설정한 값보다 특정 토큰의 df 값이 더 적게 나오면 벡터화 과정에서 제거하는걸 의미하고, analyzer은 분석을 위한 기준 단위로 'word' 와 'char' 2가지 옵션이 있는데 'word'는 단어 하나를 단위로 하는 것이고, 'char'는 문자 하나를 단위로 하는 것이다. 여기서는 문자를 단위로 하기에 'char'로 설정한다. sublinear_tf는 문서의 단어 빈도 수에 대한 스무딩(smoothing) 여부를 설정하는 값, ngram_range는 빈도의 기본 단위를 어느 범위의 n-gram으로 설ㅈ어할 것인지 보는 인자이다. 마지막으로 max_features은 각 벡터의 최대 길이, 특징의 길이 설정.
우선 TfIdfVectorizer를 생성한 후 fit_transform 함수를 사용해 전체 문장에 대한 특징 벡터 데이터 X를 생성했다. 여기까지가 TF-IDF로 벡터화.
학습과 검증 데이터셋 분리
이제 입력값을 모델에 적용하면 되는데, 그전에 우선 학습데이터의 일부를 검증 데이터로 따로 분리한다. 2장에서 사용했던 사이킷런 라이브러리에 train_test_split 함수를 활용해 학습 데이터와 검증데이터로 나눈다.
from sklearn.model_selection import train_test_split RANDOM_SEED=42 TEST_SPLIT=0.2 y=np.array(sentiments) X_train, X_eval, y_train, y_eval=train_test_split(X, y, test_size=TEST_SPLIT, random_state=RANDOM_SEED)입력값인 X와 정답 라벨을 넘파이 배열로 만든 y에 대해 적용하여 학습 데이터와 검증 데이터로 나눴다. 비율은 기존 학습 데이터의 20%로 설정해 검증 데이터를 만들었다. 이제 학습 데이터를 모델에 적용한다.
모델 선언 및 학습
선형 회귀 모델을 만들기 위해 사이킷런의 LogisticRegression 클래스 객체를 생선하고 이 객체의 fit 함수를 호출하면 데이터에 대한 모델 학습이 진행된다.
from sklearn.linear_model import LogisticRegression lgs=LogisticRegression(class_weight='balanced') lgs.fit(X_train, y_train)모델을 만들고 데이터에 적용한다. 인자값은 class_weight를 'balanced'로 설정해서 각 라벨에 대해 균형 있게 학습할 수 있게 했다.
검증 데이터로 성능 평가
검증 데이터를 가지고 학습한 모델에 대해 성능을 확인한다. 성능 평가는 앞서 학습한 객체의 score 함수를 이용하면 간단하게 측정한다.
# 검증 데이터로 성능 측정 print("Accuracy: {:f}".format(lgs.score(X_eval, y_eval)))Accuracy: 0.859800
여기서는 정확도만 측정했지만, 이 외에 정밀도, 재현율, f1-score, auc등 다양한 지표가 있다.
약 86%의 정확도를 보였다. 이 성능은 앞으로 모델을 어떻게 튜닝해서 성능을 높일 수 있는지 볼 수 있는 하나의 기준 지표가 될 수 있다. 성능이 잘 나오지 않는다면 하이퍼파라미터를 수정하거나 다른 기법을 추가해서 성능을 올린다. 검증 데이터의 성능이 만족하도록 나온다면 평가 데이터를 적용하면 된다.
데이터 제출하기
이제 만든 모델을 활용해 평가 데이터 결과를 예측하고 캐글에 제출하도록 파일로 저장한다.
우선 전처리한 텍스트 형태의 평가 데이터를 불러온다.
TEST_CLEAN_DATA='test_clean.csv' test_data=pd.read_csv(DATA_IN_PATH + TEST_CLEAN_DATA, header=0, quoting=3)학습 데이터와 마찬가지로 판다스를 통해 데이터프레임 형태로 불러온다.
이제 해당 테이터를 대상으로 이전에 학습 데이터에 대해 사용했던 객체를 사용해 TF-IDF 값으로 벡터화한다.
testDataVecs=vectorizer.transform(test_data['review'])벡터화할 때 평가 데이터에 대해서는 fit을 호출하지 않고 그대로 transform만 호출한다. fit은 학습 데이터에 맞게 설정했고, 그 설정에 맞게 평가 데이터도 변환됨.
이 값으로 예측한 후 예측값을 하나의 변수로 할당하고 출력해서 형태를 보면,
test_predicted=lgs.predict(testDataVecs) print(test_predicted)
데이터에 대해 긍정, 부정 값을 가지고 있는데 이 값을 캐글에 제출하기 위해 데이터프레임 형태로 만들어 csv 파일로 저정해야 한다. 캐글에 제출하기 위한 데이터 형식은 각 데이터의 고유한 id값과 결괏값으로 구성돼 있어야 함.
경로 지정 후 데이터 프레임을 생성해서 csv파일로 만든다.
DATA_OUT_PATH='./data_out/' if not os.path.exists(DATA_OUT_PATH): os.makedirs(DATA_OUT_PATH) ids=list(test_data['id']) answer_dataset=pd.DataFrame({'id':ids, 'sentiment':test_predicted}) answer_dataset.to_csv(DATA_OUT_PATH + 'lgs_tfidf_answer.csv',index=False)그리고 캐글에 제출하면

캐글 제출하기 
성능 결과 [ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 영어 텍스트 분류 (5) (0) 2020.12.22 [ NLP ] 영어 텍스트 분류 (4) (0) 2020.12.14 [ NLP ] 영어 텍스트 분류 (2) (0) 2020.12.09 [ NLP ] 영어 텍스트 분류 (1) (0) 2020.12.08 [ kaggle ] kaggle api 사용하기 (0) 2020.12.08 댓글