-
[ NLP ] 영어 텍스트 분류 (1)2020년 12월 08일 20시 47분 53초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
kaggle의 Bag of words Meets Bag of Popcorn이라는 문제를 활용하여 영화 리뷰 데이터를 분류한다.
(주소 : www.kaggle.com/c/word2vec-nlp-tutorial )
문제 소개
영어 텍스트 분류 문제 중 캐글의 워드팝콘 문제 활용
워드 팝콘?
워크 팝콘은 인터넷 영화 데이터베이스에서 나오느영화 평점 데이터를 활용한 캐글 문제.
영화 평점 데이터이므로 각 데이터는 영화 리뷰 텍스트와 평점에 따른 감정 값(긍정 or 부정)으로 구성됨.
목표
크게 3가지 과정을 거치는데,
첫 번째는 데이터를 불러오고 정제되지 않은 데이터를 활용하도록 전처리 과정
그 다음은 데이터를 분석하는 과정인데 데이터가 어떻게 구성돼 있는지 확인하고 그에 따라 어떻게 문제를 풀어가는지 알아본다.마지막으로 실제로 문제를 해결하기 위해 알고리즘을 모델링 하는 과정이다. (한 가지 방법이 아닌 여러 방법을 구현하고 비교)
데이터 분석 및 전처리 (전처리는 다음 게시물)
사용하는 영화 리뷰 데이터는 덱스트 분류에서 가장 기본적으로 사용되는 데이터다. 여기서는 이 데이터를 분류할 수 있는 모델을 학습시킨다. 모델을 학습시키기 전에 전처리를 거쳐야한다.그 전에 데이터를 불러오고 분석하는 과정을 선행한다. 데이터 분석은 전에 알아본 탐색적 데이터 분석(EDA)과정이다.아래는 앞으로 진행할 작업을 도식화한 것

워드팝콘 데이터의 처리 과정 데이터 불러오기 및 분석
데이터를 받는 방법은 사이트에서 직접 받거나 kaggle api를 사용해 받을 수 있다. api를 사용할 경우 powershell에
kaggle competitions download -c word2vec-nlp-tutorial
를 입력한다.
만약 kaggle을 처음 사용한다면 yanoo.tistory.com/26 를 통해 캐글 설치 후 진행한다.
우선 samplesampleSubmission.csv 파일을 제외하고 나머지가 zip으로 되어 있기 때문에 압축푸는 과정을 zipfile 라이브러리를 사용한다. 압축을 풀기 위해 경로와 압축을 풀 파일명을 리스트로 선언해야 한다. 우선 진행중인 프로젝트 폴더에 data_in이라는 폴더를 만들고 그 곳에 파일들을 압축을 푼다.

import numpy as np import pandas as pd import os import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline # 그래프를 주피터 노트북에서 바로 그리도록 함 DATA_IN_PATH='./data_in/' file_list=['labeledTrainData.tsv.zip', 'unlabeledTrainData.tsv.zip', 'testData.tsv.zip'] train_data=pd.read_csv(DATA_IN_PATH+"labeledTrainData.tsv", header=0, delimiter="\t", quoting=3)데이터를 불러올 때 pandas의 read_csv를 사용하고 함수 인자를 보면 먼저 데이터 경로를 설정한다. 그리고 현 데이터는 탭(\t)으로 구분 되어 있으므로 delimiter 인자에 "\t"를 설정한다. 그리고 각 항목명이 포함되어 있기에 header에 0으로 표시하고 쌍따옴표를 무시하기 위해 quoting 인자에 3을 설정함.
head함수로 앞 5개 데이터를 확인해보면
train_data.head()
데이터는 "id", "sentiment", "review"로 구분도 있고 각 리뷰에 대한 감정이 sentiment이다(긍정:1, 부정:0)
데이터 분석은 아래 순서로 진행한다.
- 데이터 크기
- 데이터의 개수
- 각 리뷰의 문자 길이 분포
- 많이 사용된 단어
- 긍정, 부정 데이터의 분포
- 각 리뷰의 단어 개수 분포
- 특수문자 및 대문자, 소문자 비율
우선 데이터의 크기를 확인한다.
print("파일 크기 : ") for file in os.listdir(DATA_IN_PATH): if 'tsv' in file and 'zip' not in file: print(file.ljust(30)+str(round(os.path.getsize(DATA_IN_PATH+file)/1000000,2))+'MB')
os 라이브러리로 해당 경로의 파일 목록을 가져오고, 해당 폴더에서 tsv파일 중 zip파일이 아닌 파일들만 크기를 출력한다. 라벨이 있는 학습 데이터와 평가 데이터의 크기는 비슷하고, 라벨이 없는 학습 데이터의 크기가 가장 큰 것을 볼 수 있다.
불러온 학습 데이터 개수를 보면
print('전체 학습 데이터의 개수: {}'.format(len(train_data)))
다음은 각 데이터의 문자의 길이를 본다. 'review' 열에 각 데이터의 리뷰가 있는데 각 리뷰의 길이를 새로운 변수로 정의하고 head함수를 사용해 몇개의 데이터만 확인해보면
train_length=train_data['review'].apply(len) train_length.head()
해당 변수에는 각 리뷰의 길이가 담겨 있다. 이 변수로 히스토그램을 그려본다.
# 그래프에 대한 이미지 크기 선언 # figsize:(가로, 세로) 형태의 튜플로 입력 plt.figure(figsize=(12,5)) # 히스토그램 선언 # bins : 히스토그램 값에 대한 버킷 범위 # range : x축 값의 범위 # alpha : 그래프 색상 투명도 # color : 그래프 색상 # label : 그래프에 대한 라벨 plt.hist(train_length, bins=200, alpha=0.5, color='r', label='word') plt.yscale('log', nonposy='clip') # 그래프 제목 plt.title('Log-Histogram of length of review') # 그래프 x 축 라벨 plt.xlabel('Length of review') # 그래프 y 축 라벨 plt.ylabel('Number of review')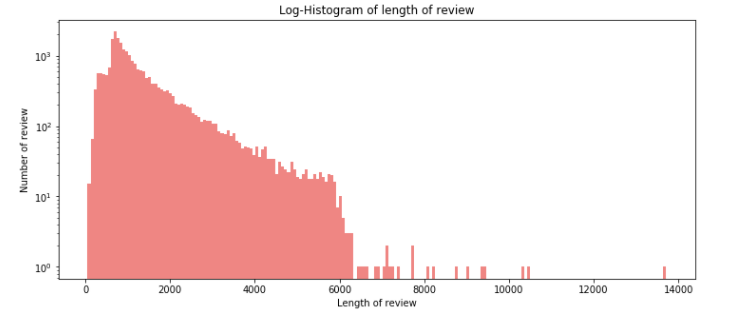
리뷰 길이 히스토그램 분포를 보면 각 리뷰의 문자 길이가 대부분 6000 이하이고 대부분 2000이하에 분포되고 일부 이상치로 10000 이상의 값을 가진다. 길이에 대한 몇 통곗값을 보면,
print('리뷰 길이 최댓값: {}'.format(np.max(train_length))) print('리뷰 길이 최솟값: {}'.format(np.min(train_length))) print('리뷰 길이 평균값: {:.2f}'.format(np.mean(train_length))) print('리뷰 길이 표준편차: {:.2f}'.format(np.std(train_length))) print('리뷰 길이 중간값: {}'.format(np.median(train_length))) # 사분위의 대한 경우는 0~100 스케일로 돼 있음 print('리뷰 길이 제1사분위: {}'.format(np.percentile(train_length, 25))) print('리뷰 길이 제3사분위: {}'.format(np.percentile(train_length, 75)))
이제 박스 플롯을 그려보면,

리뷰 길이 박스 플롯 박스 플롯을 보면 대부분 2000 이하고 평균이 1500 이하인데 길이 4000 이상의 이상치 데이터도 많다.
워드클라우드로 리뷰에 많이 사용된 단어를 보면
from wordcloud import WordCloud cloud=WordCloud(width=800, height=600).generate(" ".join(train_data['review'])) plt.figure(figsize=(20, 15)) plt.imshow(cloud) plt.axis('off')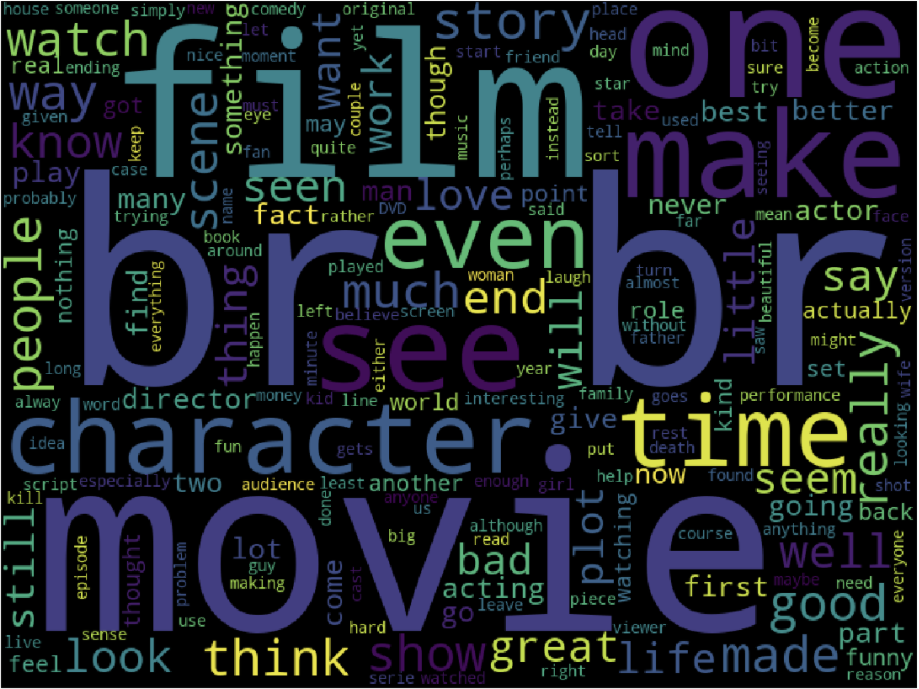
보면 br이 많은데 이런 html 태그들은 제거해야한다. 이후에 이 태그를 제거한다.
이제 각 라벨의 분포를 확인한다. 이 데이터는 긍정과 부정이라는 두 가지 라벨만 가진다. 분포의 경우 또 다른 시각화 도구인 씨본을 사용해 시각화한다.
fig, axe=plt.subplots(ncols=1) fig.set_size_inches(6,3) sns.countplot(train_data['sentiment'])
거의 동일함을 알 수 있는데 정확한 값을 확인해보면,
print("긍정 리뷰 개수: {}".format(train_data['sentiment'].value_counts()[1])) print("부정 리뷰 개수: {}".format(train_data['sentiment'].value_counts()[0]))
정확하게 같은 값을 가진다. 이제 각 리뷰를 단어 기준으로 나눠서 각 리뷰당 단어 개수를 확인한다. 단어는 띄어쓰기 기준으로 하나의 단어라고 생각하고 계산한다. 우선 단어의 길이를 가지는 변수를 하나 설정하고 히스토그램을 그린다.
# 각 단어의 길이를 가지는 변수 train_word_counts=train_data['review'].apply(lambda x:len(x.split(' '))) plt.figure(figsize=(15,10)) plt.hist(train_word_counts, bins=50, facecolor='r', label='train') plt.title('Log-Histogram of word count in review', fontsize=15) plt.yscale('log', nonposy='clip') plt.legend() plt.xlabel('Number of words', fontsize=15) plt.ylabel('Number of reviews', fontsize=15)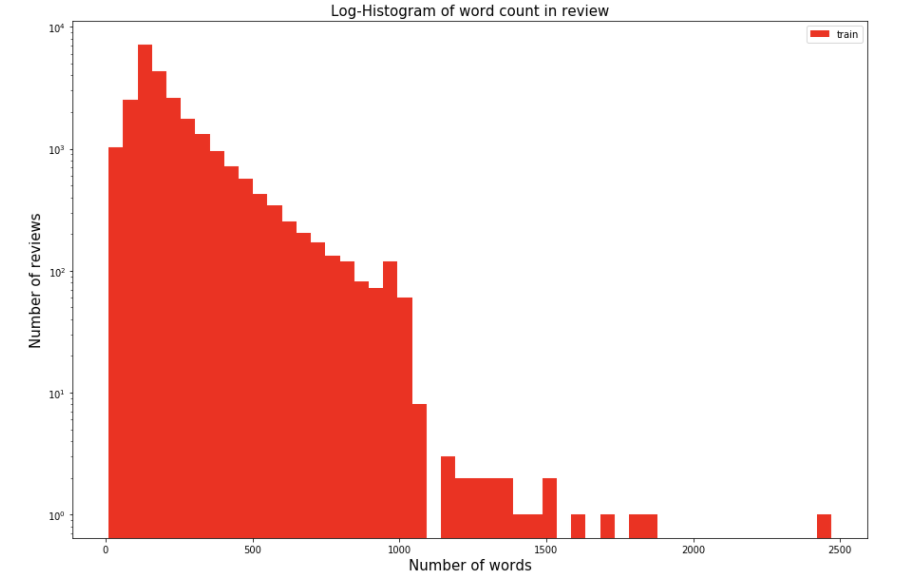
리뷰당 단어 개수에 대한 히스토그램 대부분 1000개 미만이고 대부분 200개 정도이다. 통곗값을 보면
print('리뷰 길이 최댓값: {}'.format(np.max(train_word_counts))) print('리뷰 길이 최솟값: {}'.format(np.min(train_word_counts))) print('리뷰 길이 평균값: {:.2f}'.format(np.mean(train_word_counts))) print('리뷰 길이 표준편차: {:.2f}'.format(np.std(train_word_counts))) print('리뷰 길이 중간값: {}'.format(np.median(train_word_counts))) # 사분위의 대한 경우는 0~100 스케일로 돼 있음 print('리뷰 길이 제1사분위: {}'.format(np.percentile(train_word_counts, 25))) print('리뷰 길이 제3사분위: {}'.format(np.percentile(train_word_counts, 75)))
3사분위 값이 284개로 리뷰의 75%가 300개 이하의 단어를 가짐을 알 수 있다.
마지막으로 각 리뷰에 대한 구두점과 대소문자 비율 값을 봐본다.
# 물음표가 구두점으로 쓰임 qmarks=np.mean(train_data['review'].apply(lambda x: '?' in x)) # 마침표가 구두점으로 쓰임 fullstop=np.mean(train_data['review'].apply(lambda x: '.' in x)) # 첫 번째 대문자 capital_first=np.mean(train_data['review'].apply(lambda x:x[0].isupper())) # 대문자 개수 capitals=np.mean(train_data['review'].apply(lambda x:max([y.isupper() for y in x]))) # 숫자 개수 numbers=np.mean(train_data['review'].apply(lambda x:max([y.isdigit() for y in x]))) print('물음표가 있는 질문: {:.2f}%'.format(qmarks*100)) print('마침표가 있는 질문: {:.2f}%'.format(fullstop*100)) print('첫 글자가 대문자인 질문: {:.2f}%'.format(capital_first*100)) print('대문자가 있는 질문: {:.2f}%'.format(capitals*100)) print('숫자가 있는 질문: {:.2f}%'.format(numbers*100))
결과를 보면 대부분 마침표를 포함하고, 대문자도 대부분 사용한다. 따라서 전처리 과정에서 대문자의 경우 모두 소문자로 바꾸고 특수 문자의 경우 제거한다. 이 과정은 학습에 방해 되는 요소를 제거하기 위함이다. 전처리는 다음 게시물
[ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 영어 텍스트 분류 (3) (0) 2020.12.10 [ NLP ] 영어 텍스트 분류 (2) (0) 2020.12.09 [ kaggle ] kaggle api 사용하기 (0) 2020.12.08 [ NLP ] 탐색적 데이터 분석 (0) 2020.12.05 [ NLP ] 데이터셋 (0) 2020.11.15 댓글