-
[ NLP ] 탐색적 데이터 분석2020년 12월 05일 19시 21분 47초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
처음 캐글 문제를 풀 때, 많은 사람들은 모델을 만들고 훈련 후 성능을 평가하고, 성능이 안 나온다면 다른 모델을 사용하는데, 이처럼 모델에 문제가 있는 경우도 있지만 해당 문제를 해결하려면 우선 데이터 이해가 선행돼야 한다.
이런 과정을 탐색적 데이터 분석이라고 함. 이런 과정을 통해 생각하지 못한 데이터의 여러 패턴이나 잠재적인 문제점 발견할 수 있음.
그리고 모델에 문제가 없다고 해도 데이터에 따라 맞는 모델이 있는데 모델과 데이터가 맞지 않다면 좋은 결과를 얻을 수 없다. 즉, 아무리 좋은 모델이라해도 데이터와 안 맞는 모델이라면 문제가 발생할 수 있다.
탐색적 데이터 분석은 어떻게 진행되는가?
답은 정해진 틀 없이 데이터에 대한 많은 정보를 내면 된다. (데이터에 대한 정보란? 데이터의 평균값, 중앙값, 최솟값, 최댓값, 범위, 분포, 이상치 등이 있음)
이런 값들을 확인하고 그래프 등으로 시각화 하여 데이터에 대한 직관을 얻어야 함.
데이터를 분석할 때는 기존 선입견을 배제하고 데이터가 보여주는 수치만으로 분석을 진행해야 함.

위 그림은 탐색적 데이터 분석의 전체 흐름도이며, 서로의 결과에 직접적으로 영향을 줄 수 있다는 것을 확인할 수 있음.
간단한 실습을 보면 실습 데이터는 영화 리뷰 데이터로, 리뷰와 그 리뷰에 대한 감정(긍정, 부정) 값을 가지고 있다.
데이터의 경우 라이브러리를 사용해 설치할 수 있다.
데이터 이름 acllmdb_v1 데이터 용도 탐색적 데이터 분석 데이터 권한 MIT 데이터 출처 http://ai.stanford.edu/~amaas/data/sentiment import os import re import pandas as pd import tensorflow as tf from tensorflow.keras import utils data_set=tf.keras.utils.get_file( fname="imdb.tar.gz", origin="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz", extract=True) 텐셔플로 케라스 모듈의 get_file 함수로 IMDB 데이터를 가져오고 origin에 데이터 url을 넣으면 데이터를 다운로드하게 된다.(url의 마지막 부분은 확장자로 확장자가 tar.gz인 압축 파일)
세 번째 인자인 extract를 통해 다운한 파일의 압축 해제 여부를 지정한다. fname은 다운한 파일의 이름 재지정.
판다스로 데이터를 불러오면 쉽게 데이터 분석을 진행할 수 있다 하지만 이번은 압축 풀린 데이터가 txt로 되어 있어 불가능하다.
그래서 변환 작업에 필요한 함수 두 개를 만든다. 하나는 각 파일에서 리뷰 텍스트를 불러오는 함수, 다른 하나는 각 리뷰에 해당하는 라벨값을 가져오는 함수.
def directory_data(directory): data={} data["review"]=[] for file_path in os.listdir(directory): with open(os.path.join(directory, file_path),"r",encoding='UTF8') as file: data["review"].append(file.read()) return pd.DataFrame.from_dict(data) 첫 번째 함수는 데이터를 가져올 디렉터리를 인자로 받고 디렉터리 안의 파일들을 하나씩 가져와 그 안의 내용일 읽어 data["review"] 배열에 하나씩 넣는다. 이를 다르게 말하면 딕셔너리 타입의 data에 추가하는 것. 그리고 나서 딕셔너리를 판다스 데이터프레임으로 반들어서 반환
여기서 encoding은 UnicodeDecodeError 가 발생해서 UFT8형식으로 변환시켰다.
def data(directory): pos_df=directory_data(os.path.join(directory,"pos")) neg_df=directory_data(os.path.join(directory,"neg")) pos_df["sentiment"]=1 neg_df["sentiment"]=0 return pd.concat([pos_df,neg_df]) 두 번째 함수는 폴더 이름을 지정하면 첫 번째 함수 directory_data를 호출하는데 이때 pos폴더에 접근할 지, neg 폴더에 접근할지를 각각의 데이터프레임을 반환받는다. 이 값들은 pos_df와 neg_df에 담긴다.
pos 폴더와 neg 폴더는 각각 긍정, 부정 데이터를 나타내고 특정 폴더의 값을 가져와 라벨 작업을 하고있다.
긍정은 1, 부정은 0으로 만들고 데이터프레임을 연동.
앞서 설명한 두 함수를 호출해서 판다스 데이터프레임을 반환받는 구문을 만들면
train_df=data(os.path.join(os.path.dirname(data_set),"aclImdb","train")) test_df=data(os.path.join(os.path.dirname(data_set),"aclImdb","test")) data의 인자로 디렉터리 경로를 지정하고 이 함수를 통해 각각 훈련 데이터와 평가 데이터를 데이터프레임에 받아온다.
이렇게 만든 데이터프레임의 결과를 확인해보면
train_df.head()판다스의 데이터프레임으로 부터 리뷰 문장 리스트를 가져오는 함수를 만들어 보면,
reviews=list(train_df['review'])reviews에는 각 문장을 리스트로 담고 있다. 다음으로 단어를 토크나이징하고 문장마다 토크나이징 단어의 수를 정하고 그 단어들을 붙여 알파벳의 전체 개수를 저장하는 부분을 만들면
# 문자열 문장 리스트를 토크나이징 tokenized_reviews=[r.split() for r in reviews] # 토크나이징된 리스트에 대한 각 길이를 저장 review_len_by_token=[len(t) for t in tokenized_reviews] # 토크나이징된 것을 붙여서 음절의 길이를 저장 review_len_by_eumjeol=[len(s.replace(' ','')) for s in reviews] 위 같이 만드는 이유는 문장에 포함된 단어와 알파벳 개수에 대한 데이터 분석을 수월하게 하기 위함.
이제 실제 데이터 분석을 진행한다. 먼저 히스토그램으로 문장을 구성하는 단어의 개수와 알파벳 개수를 알아보면,
import matplotlib.pyplot as plt # 그래프에 대한 이미지 크기 선언 # figsize:(가로,세로) 형태의 튜플로 입력 plt.figure(figsize=(12,5)) # 히스토그램 선언 # bins: 히스토그램 값에 대한 버킷 범위 # alpha: 그래프 색상 투명도 # color: 그래프 색상 # label: 그래프에 대한 라벨 plt.hist(review_len_by_token,bins=50,alpha=0.5,color='r',label='word') plt.hist(review_len_by_eumjeol,bins=50,alpha=0.5,color='b',label='alphabet') plt.yscale('log',nonposy='clip') # 그래프 제목 plt.title('Review Length Histogram') # 그래프 x 축 라벨 plt.xlabel('Review Length') # 그래프 y 축 라벨 plt.ylabel('Number of Reviews') 
데이터 길이에 대한 히스토그램 지금 데이터를 통해 보려는 내용은 문장에 대한 길이 분포로 빨간색은 단어 개수에 대한 히스토그램, 파란색은 알파벳 개수의 히스토그램.
단어 단위와 알파벳의 전체적인 분포를 시각적으로 볼 수 있으며 이상치(outliers) 값을 확인할 수 있다.
다음으로 데이터 분포를 통계치로 수치화한다.
import numpy as np print('문장 최대 길이: {}'.format(np.max(review_len_by_token))) print('문장 최초 길이: {}'.format(np.min(review_len_by_token))) print('문장 평균 길이: {:.2f}'.format(np.mean(review_len_by_token))) print('문장 길이 표준편차: {:.2f}'.format(np.std(review_len_by_token))) print('문장 중간 길이: {}'.format(np.median(review_len_by_token))) # 사분위에 대한 경우 0~100 스케일로 돼 있음 print('제1사분위 길이: {}'.format(np.percentile(review_len_by_token,25))) print('제3사분위 길이: {}'.format(np.percentile(review_len_by_token,75))) 문장 최대 길이: 2470
문장 최초 길이: 10
문장 평균 길이: 233.79
문장 길이 표준편차: 173.73
문장 중간 길이: 174.0
제1사분위 길이: 127.0
제3사분위 길이: 284.0여기서 사분위 지점은 전체 데이터에서 1/4, 3/4 지점을 말한다. 이러한 통계값을 통해 수치적으로 데이터 문장 길이의 분포를 확인할 수 있다.
다음으로 박스 플롯으로 데이터를 수치화한다. 박스 플롯은 직관적인 시각화를 제동한다. 문장 내 단어 수와 문장에 알파벳 개수를 각각 따로 박스 플롯으로 만들어볼 것이다.
plt.figure(figsize=(12,5)) # 박스 플롯 생성 # 첫 번째 인자: 여러 분포에 대한 데이터 리스트를 입력 # labels: 입력한 데이터에 대한 라벨 # showmeans: 평균값을 마크함 plt.boxplot([review_len_by_token],labels=['token'],showmeans=True) 
문장 내 단어 수에 대한 히스토그램 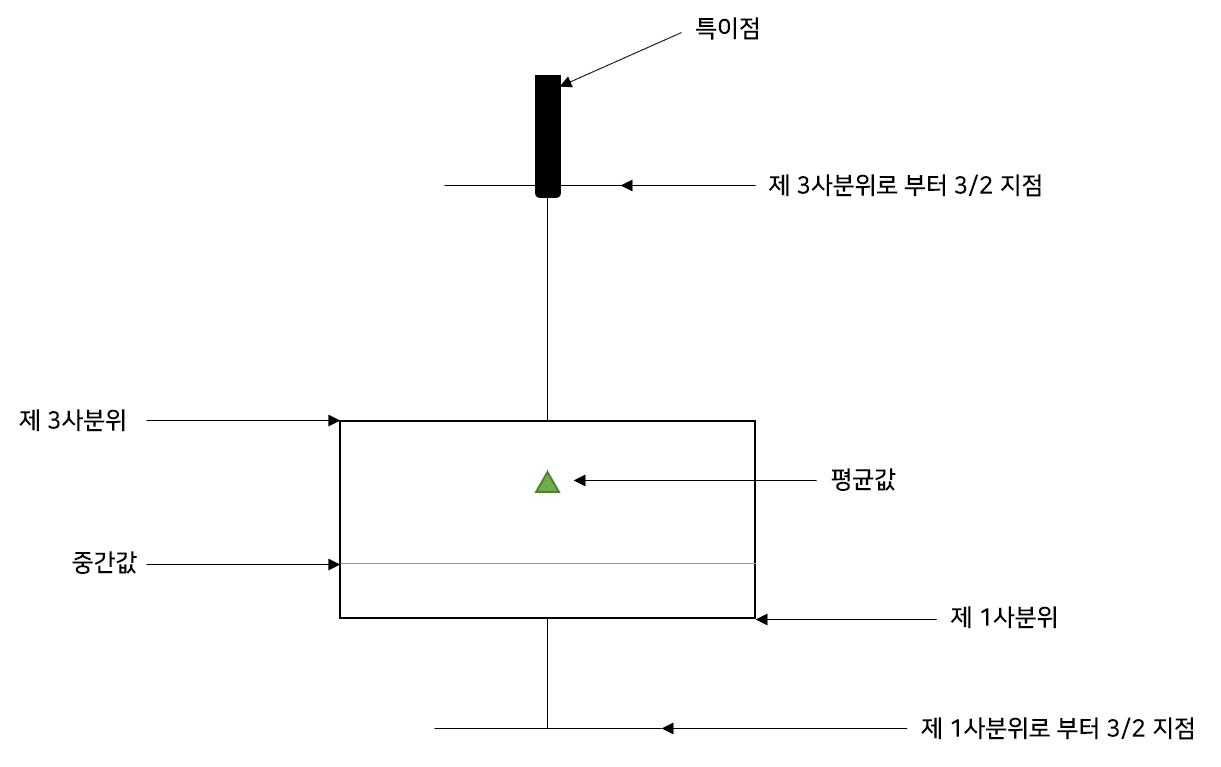
확대된 박스 플롯 앞에서 수치화했던 다양한 값들을 박스 플롯을 통해 볼 수 있고, 전체적인 데이터 분포를 확인할 수 있음. 또한 박스 플롯을 통해 이상치가 심한 데이터 확인 가능.
문장의 알파벳 개수를 나타내는 박스 플롯을 만들면
plt.figure(figsize=(12,5)) plt.boxplot([review_len_by_eumjeol],labels=['Eumjeol'],showmeans=True) 
문장 내 알파벳 개수에 대한 히스토그램 이 박스 플롯도 이전과 유사하게 이상치가 심한 데이터를 확인할 수 있다. 이상치가 심하면 데이터 범위가 너무 넓어 학습이 효율적으로 이뤄지지 않는다.
워크 클라우드로 데이터를 시각화해보면
from wordcloud import WordCloud, STOPWORDS import matplotlib.pyplot as plt %matplotlib inline wordcloud=WordCloud(stopwords=STOPWORDS, background_color='black',width=800,height=600).generate(' '.join(train_df['review'])) plt.figure(figsize=(15,10)) plt.imshow(wordcloud) plt.axis("off") plt.show() 
워드클라우드 결과 보면 html 태그인 <br>과 같은 게 많은데 이것들은 제거해야한다.
마지막으로 긍정 부정 분포를 확인한다.
import seaborn as sns import matplotlib.pyplot as plt sentiment=train_df['sentiment'].value_counts() fig,axe=plt.subplots(ncols=1) fig.set_size_inches(6,3) sns.countplot(train_df['sentiment']) 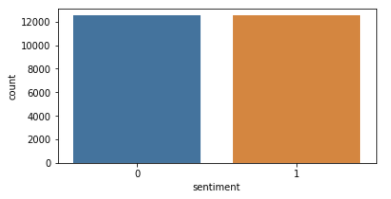
긍정 부정의 분포 결과 긍정과 부정의 개수가 12000개로 같은데 이것은 데이터의 균형이 아주 좋다는 것을 의미한다.
[ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 영어 텍스트 분류 (1) (0) 2020.12.08 [ kaggle ] kaggle api 사용하기 (0) 2020.12.08 [ NLP ] 데이터셋 (0) 2020.11.15 [ NLP ] 기계 이해 (0) 2020.11.14 [ NLP ] 텍스트 유사도 ( 유클리디언 유사도, 맨하탄 유사도 ) (0) 2020.11.10 댓글
