-
[ NLP ] 텍스트 유사도 ( 자카드 유사도, 코사인 유사도 )2020년 10월 26일 19시 49분 48초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
- 이 소설 쓴 사람이 누구야?
- 내가 보고 있는 소설 작가가 누구야?
두 문장은 같은 의미이지만 인공지능 스피커는 다른 문장으로 인식한다. 효율성을 위해 같은 대답을 준비해야하고
이때 문장이 유사한지 측정해야하며, 텍스트 유사도 측정 방법을 사용해 이를 측정한다.
텍스트 유사도
: 텍스트가 얼마나 유사한지를 표한하는 방식 중 하나
일반적으로 유사도를 측정하기 위해 정량화 하는 방법에는
- 단순히 같은 단어의 개수를 사용하여 유사도를 판단하는 방법
- 형태소로 나눠 형태소를 비교하는 방법
- 자소 단위로 나누어 단어를 비교하는 방법
이 중 딥러닝을 기반으로 텍스트의 유사도를 측정하는 방식을 보면
단어, 형태소, 유사도의 종류에 상관 없이, 텍스트를 벡터화한 후 벡터화된 문장들 간의 유사도를 측정하는 방법이다.
그리고 자주 사용되는 4개의 유사도 측정 방법을 보면 자카드 유사도, 유클리디언 유사도, 맨하탄 유사도, 코사인 유사도가 있다.
일단 유사도를 측정하기 전 한 가지 예시를 보면
- 휴일인 오늘도 서쪽을 중심으로 폭염이 이어졌는데요, 내일은 반가운 비 소식이 있습니다.
- 폭염을 피해서 휴일에 놀러왔다가 갑작스런 비로 인해 망연자실하고 있습니다.
이 두 문장을 유사도 측정하기 전 벡터화 한다. TF-IDF를 통해 벡터화 하면
from sklearn.feature_extraction.text import TfidfVectorizer sent=("휴일 인 오늘 도 서쪽 을 중심 으로 폭염 이 이어졌는데요, 내일 은 반가운 비 소식 이 있습니다.", "폭염 을 피해서 휴일 에 놀러왔다가 갑작스런 비 로 인해 망연자실 하고 있습니다.") tfidf_vectorizer=TfidfVectorizer() tfidf_matrix=tfidf_vectorizer.fit_transform(sent) idf=tfidf_vectorizer.idf_ print(dict(zip(tfidf_vectorizer.get_feature_names(),idf))){'갑작스런': 1.4054651081081644, '내일': 1.4054651081081644, '놀러왔다가': 1.4054651081081644, '망연자실': 1.4054651081081644, '반가운': 1.4054651081081644, '서쪽': 1.4054651081081644, '소식': 1.4054651081081644, '오늘': 1.4054651081081644, '으로': 1.4054651081081644, '이어졌는데요': 1.4054651081081644, '인해': 1.4054651081081644, '있습니다': 1.0, '중심': 1.4054651081081644, '폭염': 1.0, '피해서': 1.4054651081081644, '하고': 1.4054651081081644, '휴일': 1.0}
1. 자카드 유사도
: 두 문장을 각각 단어의 집합으로 만든 뒤 두 집합을 통해 유사도를 측정하는 방식 중 하나.
두 집합의 교집합인 공통된 단어의 개수를 두 집합의 합집합, 즉 전체 단어의 수로 나누면됨.
결과값은 공통의 원소의 개수에 따라 0~1사이 값을 갖고, 1에 가까울 수록 유사도가 높다는 의미이다.

자카드 유사도 공식 위 수식은 자카드 유사도를 나타내는 수식인데 A,B는 각 문장을 의미하고 token은 각 단어를 의미한다.
위의 예시로 A, B를 확인해보면
A = {휴일, 인, 오늘, 도, 서쪽, 을, 중심, 으로, 폭염, 이, 이어졌는데요, 내일, 은, 반가운, 비, 소식, 있습니다.}B = {폭염, 을, 피해서, 휴일, 에, 놀러왔다가, 갑작스런, 비, 로, 인해, 망연자실, 하고, 있습니다.}

자카드 공식에 대입해 보면 교집합은 6개 합집합은 24개 이므로 6/24=0.25가 된다.
2. 코사인 유사도
: 두 개의 벡터값에서 코사인 각도를 구하는 방법.
-1~1값을 가지고 1에 가까울수록 유사하다는 것을 의미한다.
다른 유사도 방법에 비해 일반적으로 성능이 좋은데 이는 방향성의 개념이 더해지기 때문이다.
유사하다면 같은 방향을 가리키고, 유사하지 않을수록 직교로 표현된다.
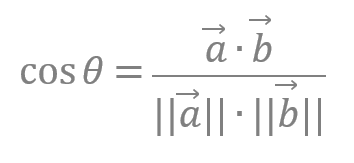
코사인 유사도 공식 코사인 유사도의 경우 직접 함수 구현이 필요없고 사이킷런에서 측정을 위한 함수를 제공한다.
from sklearn.metrics.pairwise import cosine_similarity cosine_similarity(tfidf_matrix[0:1],tfidf_matrix[1:2])array([[0.17952266]])
코사인 유사도에서 문장 A와 문장 B의 유사도는 0.179으로 산출된다.
[ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 기계 이해 (0) 2020.11.14 [ NLP ] 텍스트 유사도 ( 유클리디언 유사도, 맨하탄 유사도 ) (0) 2020.11.10 [ NLP ] 텍스트 분류 (1) 2020.10.24 [ NLP ] 원-핫 인코딩과 분포 가설 (2) 2020.10.21 [ Beautiful Soup ] Beautiful Soup 설치와 html 태그 제거 (2) 2020.10.03 댓글