-
[ NLP ] 텍스트 분류2020년 10월 24일 01시 09분 59초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
텍스트 분류는 자연어 처리 문제 중 가장 대표적이고 많이 접하는 문제이다.
자연어 처리 기술을 활용해 특정 텍스트를 사람이 정하는 범주 중 어느 범주에 속하는지 분류하는 문제
보통 2가지 범주에 대해 구분하는 문제를 이진 분류,
3가지 이상을 구분하는 문제를 다중 범주 분류라고 한다.
예시를 보면
1. 스팸 분류
여기서 분류해야할 범주는 일반 메일과 스팸 메일 두 가지이다.
2. 감정 분류
주어진 글에 대해 이 글이 긍정적인지 부정적인지 판단하는 문제
3. 뉴스 기사 분류
다양한 분류를 가지는 뉴스 기사를 사용자가 원하는 뉴스 파트별로 분리하는 것
4. 지도학습을 통한 텍스트 분류
글에 대해 각각 속한 범주에 대한 값(라벨)이 이미 주어져 있고, 주어진 범주로 글들을 모두 학습한 후 학습한 결과를 이용해 새로운 글의 범주를 예측하는 방법
대표적 지도학습 모델 : 나이브 베이즈 분류, 서포트 벡터 머신, 신경망, 선형 분류, 로지스틱 분류, 랜덤 포레스트
5. 비지도학습을 통한 텍스트 분류
데이터만 존재하고, 각 데이터가 범주별로 미리 나눠져 있지 않는다. 그래서 특성을 찾아내서 적당한 범주를 만들어 데이터를 나누는 방법.
대표적인 방법으로 k-평균 군집화를 예로 들면

각 문장의 데이터를 벡터화한 후 위의 좌표축처럼 표현한다. 이후 k-평균 군집화 모델을 사용해 몇개의 군집으로 나눈다.(여기서는 k값을 4)
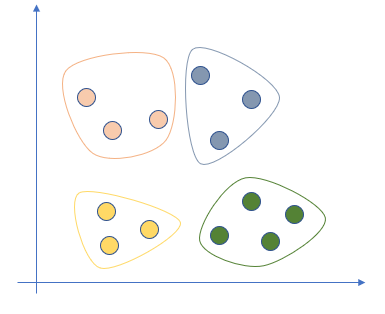
그림과 같이 4개의 군집으로 나뉜다. 어떤 특정한 분류가 있는 것이 아니라 데이터의 특성에 따라 비슷한 데이터끼리 묶어주는 개념이다.
대표적인 비지도학습 모델 : k-평균 군집화, 계층적 군집화
지도학습과 비지도학습의 기준은 데이터에 정답 라벨의 유무이다. 있다면 지도학습, 없다면 비지도학습을 사용해 문제를 해결한다.
[ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 텍스트 유사도 ( 유클리디언 유사도, 맨하탄 유사도 ) (0) 2020.11.10 [ NLP ] 텍스트 유사도 ( 자카드 유사도, 코사인 유사도 ) (0) 2020.10.26 [ NLP ] 원-핫 인코딩과 분포 가설 (2) 2020.10.21 [ Beautiful Soup ] Beautiful Soup 설치와 html 태그 제거 (2) 2020.10.03 [ NLP ] 토크나이징 (0) 2020.09.23 댓글