-
[ NLP ] 텍스트 유사도 (1)2021년 01월 30일 00시 58분 37초에 업로드 된 글입니다.작성자: Yanoo728x90반응형
자연어 처리의 다른 문제인 텍스트 유사도 문제를 풀 것이다.
문제는 캐글에서 "Quora Questions Pairs"문제이다. Quora는 질문을 하고 다른 사용자로부터 답을 받을 수 있는 서비스로 이 서비스에 올라온 질문 중 어떤 질문이 서로 유사한지 판단하는 모델을 만드는 것이 목표다.
문제 소개
www.kaggle.com/c/quora-question-pairs/data
Quora Question Pairs
Can you identify question pairs that have the same intent?
www.kaggle.com
실제로 딥러닝 공부할 때도 쿼라 질문들로 공부할 수 있다.
우선 데이터에 대해 알아보고 데이터를 분석 그 결과로 데이터 전처리를 진행한다.
데이터 분석과 전처리
여기서는 문장 길이와 어휘 빈도 분석으로 데이터 분석을 진행하고 그 결과를 전처리한다.

I Understand and accept로 동의한 후 powershell에 다음을 입력한다.
kaggle competitions download -c quora-question-pairs
안의 파일들은
- sample_submission.csv
- test.csv.zip
- train.csv.zip
인데, train.csv.zip과 test.csv.zip 파일은 각각 학습 데이터와 평가 데이터를 뜻한다. sample_submission.csv.zip은 우리가 만든 모델을 통해 평가데이터에 대한 예측 결과를 캐글 홈페이지에 제출할 때 양식을 맞추기 위해 보여주는 예시 파일이다.
'data_in2' 폴더를 만든 후 여기에 압축을 풀것이다.
import zipfile DATA_IN_PATH='./data_in2/' file_list=['train.csv.zip','test.csv.zip','sample_submission.csv.zip'] for file in file_list: zipRef=zipfile.ZipFile(DATA_IN_PATH+file,'r') zipRef.extractall(DATA_IN_PATH) zipRef.close()압축을 풀었다면 패키지를 모두 불러온다.
import numpy as np import pandas as pd import os import matplotlib.pyplot as plt import seaborn as sns from pathlib import Path %matplotlib inline다음으로 학습 데이터가 어떤 데이터로 구성돼 있는지 판다스의 데이터 프레임 형태로 불러와 확인한다.
train_data=pd.read_csv(DATA_IN_PATH+'train.csv') train_data.head()
'is_quplicate는 0 또는 1값을 가지는데 0은 두 질문이 중복이 아니고 1이면 두 질문이 중복이라는 것이다.
이제 사용할 데이터에 대해 봐보자.
print("파일 크기: ") for file in os.listdir(DATA_IN_PATH): if 'csv' in file and 'zip' not in file: print(file.ljust(30)+str(round(os.path.getsize(DATA_IN_PATH+file)/1000000,2))+'MB')
보통 훈련 데이터가 평가 데이터보다 큰데, 이번은 평가가 훈련 데이터보다 5배 정도 크다. 평가 데이터가 큰 이유는 쿼라는 질문에 대해 데이터 수가 적다면 각 검색을 통해 중복을 찾아내는 편법을 사용가능한데, 이런 것을 방지하기 위해 쿼라에서 직접 컴퓨터가 만든 질문 쌍을 평가 데이터에 임의적으로 추가했기 때문이다. 따라서 평가 데이터가 크지만 실제 질문 데이터는 적다. 그리고 캐글은 예측 결과를 제출하면 점수를 받는데, 컴퓨터가 만든 질문쌍 예측은 점수에 포함되지 않는다.
학습 데이터 개수를 보면
print('전체 학습 데이터의 개수: {}'.format(len(train_data)))
전체 질문 쌍 개수는 40만 개다. 판다스는 데이터프레임과 시리즈라는 자료구조를 가지는데, 데이터프레임이 행렬 구조라면, 시리즈는 인덱스를 가지고 있는 배열이다. 지금 하나의 데이터에 두 개의 질문이 있는 구조인데, 전체 질문(두 개의 질문)을 한 번에 분석하기 위해 판다스의 시리즈를 통해 두 개의 질문을 하나로 합친다.
참고로 진행 분석 순서는 질문 중복 분석, 라벨 빈도 분석, 문자 분석, 단어 분석이다. 질문 중복 분석부터 시작하면,
train_set=pd.Series(train_data['question1'].tolist()+train_data['question2'].tolist()).astype(str) train_set.head()
각 질문을 리스트로 만든 후 하나의 시리즈 데이터 타입으로 만든다. 결과를 보면 위의 구조로 합쳐졌다. 기존 데이터에서 질문 쌍의 수가 40만 개 정도이고 각 질문이 두 개이므로 대략 80만 개 정도의 질문이 있다.
이제 중복 여부를 확인한다. 넘파이로 중복을 제거한 총 질문의 수와 반복해서 나오는 질문의 수를 확인한다.
print('교육 데이터의 총 질문 수: {}'.format(len(np.unique(train_set)))) print('반복해서 나타나는 질문의 수: {}'.format(np.sum(train_set.value_counts()>1)))
80만개중 53만 개가 유니크 데이터이므로 27만 개가 중복임을 알 수 있고, 27만 개의 데이터는 11만 개 데이터의 교유한 질문으로 이뤄져 있다는 것을 알 수 있다.
이를 맷플롯립으로 시각화한다.
# 그래프에 대한 이미지 사이즈 선언 # figsize: (가로, 세로) 형태의 튜플로 입력 plt.figure(figsize=(12,5)) # 히스토그램 선언 # bins : 히스토그램 값들에 대한 버켓 범위 # range : x축 값의 범위 # alpha : 그래프 색상 투명도 # color : 그래프 색상 # label : 그래프에 대한 라벨 plt.hist(train_set.value_counts(), bins=50, alpha=0.5, color='r', label='word') plt.yscale('log', nonposy='clip') # 그래프 제목 plt.title('Log-Histogram of question appearance counts') # 그래프 x 축 라벨 plt.xlabel('Number of occurrences of question') # 그래프 y 축 라벨 plt.ylabel('Number of questions')
우선 중복 횟수가 1인 것, 즉 유일한 질문이 가장 많고 대부분이 질문 중복이 50번 이하다. 그리고 매우 큰 빈도들은 이상치가 될 것이다.
질문 중복 분포를 통계치로 수치화해서 확인해본다.
print('중복 최대 개수: {}'.format(np.max(train_set.value_counts()))) print('중복 최소 개수: {}'.format(np.min(train_set.value_counts()))) print('중복 평균 개수: {:.2f}'.format(np.mean(train_set.value_counts()))) print('중복 표준편차: {:.2f}'.format(np.std(train_set.value_counts()))) print('중복 중간길이: {}'.format(np.median(train_set.value_counts()))) print('제1사분위 중복: {}'.format(np.percentile(train_set.value_counts(),25))) print('제3사분위 중복: {}'.format(np.percentile(train_set.value_counts(),75)))
여기서 중복이 발생하는 평균이 1.5라는 것은 많은 데이터가 최소 1개 이상 중복임을 의미한다. 즉 중복이 많다. 이제 박스 플롯을 보면
plt.figure(figsize=(12,5)) # 박스 플롯 생성 # 첫 번째 파라미터: 여러 분포에 대한 데이터 리스트를 입력 # labels: 입력한 데이터에 대한 라벨 # showmeans : 평균값을 마크함 plt.boxplot([train_set.value_counts()],labels=['counts'], showmeans=True)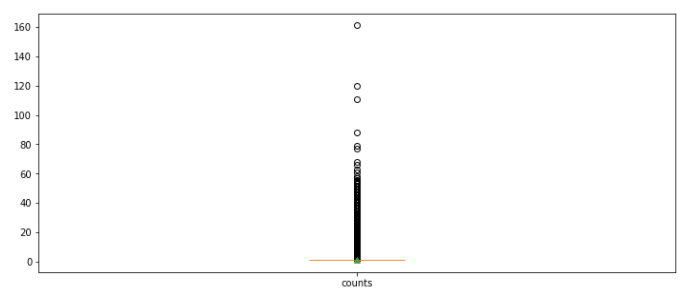
이상치가 너무 넓고 많이 분포해서 박스 플롯의 다른 값을 확인하기 어려운 데이터다.
그리고 어떤 단어가 많은지 워드클라우드를 확인해보자.
from wordcloud import WordCloud cloud=WordCloud(width=800, height=600).generate(" ".join(train_set.astype(str))) plt.figure(figsize=(15,10)) plt.imshow(cloud) plt.axis('off')
이제 질문 텍스트가 아닌 데이터의 라벨인 'is_duplicate'에 대해 보면, 라벨의 경우 중복을 뜻하는 1과 중복이 아닌 0 값이 있다. 라벨 횟수의 그래프를 그리면
fig, axe=plt.subplots(ncols=1) fig.set_size_inches(6,3) sns.countplot(train_data['is_duplicate'])40만 개에서 25만 개가 중복이 아니고, 15만 개가 중복이다. 이 상태로 학습하면 중복이 아닌 25만 개의 의존도가 높아져 데이터가 한쪽 라벨로 편향되므로 최대한 균형을 맞춰주는 것이 좋다고 한다. 많은 쪽을 줄여도 되고 적은 쪽을 늘려서 학습해도 된다.
다음으로 텍스트 데이터 길이를 분석한다. 문자 단위로 먼저 길이를 분석하고 단어 단위로 길이를 분석한다. 우선 문자 단위 분석을 위해 각 데이터 길이를 담은 변수를 생성한다.
train_length=train_set.apply(len)이 변수를 활용해 히스토그램을 그린다.
plt.figure(figsize=(15,10)) plt.hist(train_length, bins=200, range=[0,200], facecolor='r', normed=True, label='train') plt.title("Normalised histogram of character count in questions", fontsize=15) plt.legend() plt.xlabel('Number of characters', fontsize=15) plt.ylabel('Probability', fontsize=15)
각 데이터 질문의 길이는 15~150에 모여있으며 150에서 급격하게 줄어드는 것으로 보아 쿼라의 길문 길이 제한이 150 정도라는 것을 추정할 수 있다. 150이상 데이터는 거의 없기에 해당 데이터로 문제가 되지는 않을 것이다.
여러 통계를 확인해보면,
print('질문 길이 최댓값: {}'.format(np.max(train_length))) print('질문 길이 평균값: {:.2f}'.format(np.mean(train_length))) print('질문 길이 표준편차: {:.2f}'.format(np.std(train_length))) print('질문 길이 중간값: {}'.format(np.median(train_length))) print('질문 길이 제1사분위: {}'.format(np.percentile(train_length, 25))) print('질문 길이 제3사분위: {}'.format(np.percentile(train_length, 75)))
평균 길이가 60정도고 중간값은 51정도다. 하지만 최대값을 보면 1169로 평균, 중간값에 비해 배우 차이가 크다. 이런 데이터는 제외하고 학습하는 것이 좋다고 한다.
이제 데이터 질문 길이값에 대해 박스플롯을 그려본다.
plt.figure(figsize=(12,5)) plt.boxplot(train_length,labels=['char counts'],showmeans=True)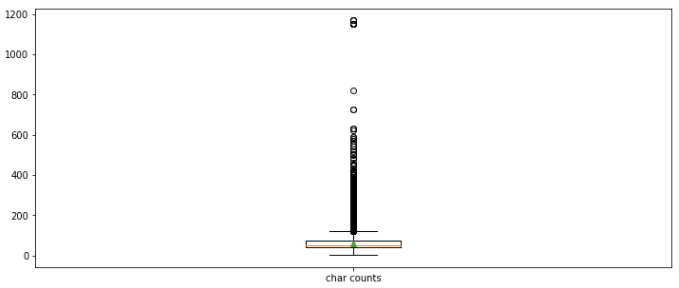
분포를 보면 문자 수의 이상치가 너무 많아 박스플롯의 다른 값 확인이 어렵다.
이제 문자를 한 단위로 하는 것이 아니라 각 데이터의 단어 개수를 하나의 단위로 사용해 길이값을 분석해보자.
하나의 단어로 나누는 기준은 단순히 띄어쓰기다. 우선 각 데이터에 대해 단어의 개수를 담은 변수를 정의한다.
train_word_counts=train_set.apply(lambda x:len(x.split(' ')))띄어쓰기 기준으로 나눈 단어의 개수를 담은 변수를 정의했고, 이제 이 값을 사용해 히스토그램을 그린다.
plt.figure(figsize=(15,10)) plt.hist(train_word_counts, bins=50, range=[0,50], facecolor='r', normed=True, label='train') plt.title('Normalised histogram of word count in questions', fontsize=15) plt.legend() plt.xlabel('Number of words', fontsize=15) plt.ylabel('Probability', fontsize=15)
보면 대부분 10개 정도 단어가 가장 많고 20개 이상 단어는 매우 적다. 데이터 단어 개수에 대해서도 통계를 확인해보자.
print('질문 단어 개수 최댓값: {}'.format(np.max(train_word_counts))) print('질문 단어 개수 평균값: {:.2f}'.format(np.mean(train_word_counts))) print('질문 단어 개수 표준편차: {:.2f}'.format(np.std(train_word_counts))) print('질문 단어 개수 중간값: {}'.format(np.median(train_word_counts))) print('질문 단어 개수 제1사분위: {}'.format(np.percentile(train_word_counts,25))) print('질문 단어 개수 제3사분위: {}'.format(np.percentile(train_word_counts,75))) print('질문 단어 개수 99퍼센트: {}'.format(np.percentile(train_word_counts,99)))
문자 단위 길이와 비슷한 양상이다. 우선 평균 개수는 히스토그램를 봤듯 11개가 평균이다. 그리고 중간값의 경우 평균보다 1 적은 10개를 가지고, 문자 길이가 최대는 1100정도이다. 단어 길이는 최대 237개이다. 해당 데이터는 지나치게 긴 문자 길이와 단어 개수를 보여준다. 박스 플롯을 확인해보면,
plt.figure(figsize=(12,5)) plt.boxplot(train_word_counts,labels=['word counts'], showmeans=True)
문자 길이 박스플롯과 비슷하다. 쿼라 데이터의 경우 이상치가 넓고 많이 분포돼 있다.
이제 마지막으로 몇 가지 특정 경우에 대한 비율을 본다.
# 물음표가 구두점으로 쓰임 qmarks=np.mean(train_set.apply(lambda x: '?' in x)) # [] math=np.mean(train_set.apply(lambda x: '[math]' in x)) # 마침표 fullstop=np.mean(train_set.apply(lambda x: '.' in x)) # 첫 번째 대문자 capital_first=np.mean(train_set.apply(lambda x: x[0].isupper())) # 대문자가 몇개 capitals=np.mean(train_set.apply(lambda x: max([y.isupper() for y in x]))) # 숫자가 몇 개 numbers=np.mean(train_set.apply(lambda x: max([y.isdigit() for y in x]))) print('물음표가 있는 질문: {:.2f}%'.format(qmarks*100)) print('수학 태그가 있는 질문: {:.2f}%'.format(math*100)) print('질문이 가득 찼을 때: {:.2f}%'.format(fullstop*100)) print('첫 글자가 대문자인 질문: {:.2f}%'.format(capital_first*100)) print('대문자가 있는 질문: {:.2f}%'.format(capitals*100)) print('숫자가 있는 질문: {:.2f}%'.format(numbers*100))
대문자가 첫 글자와 물음표 동반 질문이 99% 이상이다. 생각해볼 것이 모든 질문이 가진 보편적 특징의 유지 여부인데, 모두가 가지는 특징은 여기서는 제거한다.
지금까지 데이터 구조와 분포를 봤는데 질문 데이터의 중복 여부 분포가 크게 차이나서 학습에 편향적 정보를 제공하므로 좋지 않다고 한다. 그래서 전처리 과정에서 분포를 맞춰준다. 첫 번째 대문자는 모두 소문자로 통일하고 물음표같은 구두점은 삭제하는 식으로 보편적인 특성은 제거하여 학습하는 이점을 얻는다.
[ 출처 : 책 ( 텐서플로와 머신러닝으로 시작하는 자연어 처리) ]
728x90반응형'프로그래밍 > NLP' 카테고리의 다른 글
[ NLP ] 텍스트 유사도 (3) (2) 2021.03.09 [ NLP ] 텍스트 유사도 (2) (0) 2021.02.24 [ NLP ] 한글 텍스트 분류 (3) (0) 2021.01.21 [ NLP ] 한글 텍스트 분류 (2) (0) 2021.01.13 [ NLP ] 한글 텍스트 분류 (1) (0) 2021.01.12 댓글